Erklärte Quadratsumme
In der Statistik ist die (durch die
Regression)
erklärte Quadratsumme, bzw. erklärte Abweichungsquadratsumme, kurz
SQE für Summe der Quadrate der Erklärten
Abweichungen (englisch
sum of squared explained deviations, kurz SSE oder explained
sum of squares, kurz ESS), Summe der
Abweichungsquadrate der  -Werte, kurz
-Werte, kurz  ,
bzw. SAQErklärt, oft auch Modellquadratsumme
oder Regressionsquadratsumme, die Quadratsumme der Schätzwerte bzw.
Regresswerte. Sie wird berechnet als Summe der Quadrate der
zentrierten
Schätzwerte und kann als „Gesamtvariation der Schätzwerte
,
bzw. SAQErklärt, oft auch Modellquadratsumme
oder Regressionsquadratsumme, die Quadratsumme der Schätzwerte bzw.
Regresswerte. Sie wird berechnet als Summe der Quadrate der
zentrierten
Schätzwerte und kann als „Gesamtvariation der Schätzwerte  “
(„erklärte Variation“) interpretiert werden. Über die genaue Bezeichnung und
ihre Abkürzungen gibt es international keine Einigkeit.
In der deutschsprachigen Literatur wird manchmal die deutsche Bezeichnung mit
englischen Abkürzungen gebraucht.
“
(„erklärte Variation“) interpretiert werden. Über die genaue Bezeichnung und
ihre Abkürzungen gibt es international keine Einigkeit.
In der deutschsprachigen Literatur wird manchmal die deutsche Bezeichnung mit
englischen Abkürzungen gebraucht.
Definition
Die erklärte (Abweichungs-)Quadratsumme bzw.
Regressionsquadratsumme ist definiert als Quadratsumme der durch die
Regressionsfunktion erklärten Abweichungen  :
:

Manchmal findet sich auch die Abkürzung  bzw.
bzw.  .
Dieser Ausdruck, kann allerdings leicht mit der „Residuenquadratsumme“
(englisch
sum of squared residuals) verwechselt werden, die ebenfalls mit
abgekürzt wird.
.
Dieser Ausdruck, kann allerdings leicht mit der „Residuenquadratsumme“
(englisch
sum of squared residuals) verwechselt werden, die ebenfalls mit
abgekürzt wird.
Wenn das zugrundeliegende lineare
Modell ein von Null verschiedenes Absolutglied
 enthält, stimmt der empirische Mittelwert der Schätzwerte
enthält, stimmt der empirische Mittelwert der Schätzwerte  mit dem der beobachteten Messwerte
mit dem der beobachteten Messwerte
 überein, also
überein, also  (für einen Beweis im multiplen Fall siehe Bestimmtheitsmaß#Matrixschreibweise).
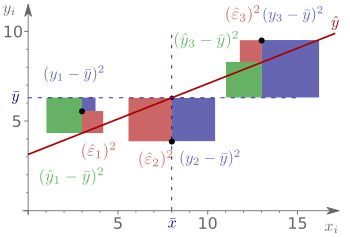
Die erklärte Quadratsumme misst die Streuung der Schätzwerte
um ihren Mittelwert
(für einen Beweis im multiplen Fall siehe Bestimmtheitsmaß#Matrixschreibweise).
Die erklärte Quadratsumme misst die Streuung der Schätzwerte
um ihren Mittelwert  .
Das Verhältnis der durch die
Regression erklärten Quadratsumme zur totalen
Quadratsumme wird Bestimmtheitsmaß
der Regression genannt.
.
Das Verhältnis der durch die
Regression erklärten Quadratsumme zur totalen
Quadratsumme wird Bestimmtheitsmaß
der Regression genannt.
Einfache lineare Regression
In der einfachen
linearen Regression (Modell mit nur einer erklärenden Variable)  lässt sich die erklärte Quadratsumme auch wie folgt ausdrücken:
lässt sich die erklärte Quadratsumme auch wie folgt ausdrücken:
 .
.
Hierbei stellen die  die vorhergesagten Werte dar und
die vorhergesagten Werte dar und  ist die Schätzung des Absolutglieds
und
ist die Schätzung des Absolutglieds
und  die Schätzung des Steigungsparameters. Aus dieser Schreibweise lässt sich
erkennen, dass sich die erklärte Quadratsumme auch darstellen lässt als Produkt
aus dem Quadrat
des Bravais-Pearson-Korrelationskoeffizienten
die Schätzung des Steigungsparameters. Aus dieser Schreibweise lässt sich
erkennen, dass sich die erklärte Quadratsumme auch darstellen lässt als Produkt
aus dem Quadrat
des Bravais-Pearson-Korrelationskoeffizienten
 und der totalen
Quadratsumme
und der totalen
Quadratsumme  :
:
 ,
,
wobei
der Kleinste-Quadrate-Schätzer
für die Steigung  der Quotient aus Produktsumme von
der Quotient aus Produktsumme von  und
und  und Quadratsumme von
ist. Um dies zu zeigen, muss zunächst gezeigt werden, dass wenn das
zugrundeliegende lineare
Modell ein von Null verschiedenes Absolutglied
enthält, der empirische Mittelwert der Schätzwerte
mit dem der beobachteten Messwerte
übereinstimmt. Dies gilt, wegen
und Quadratsumme von
ist. Um dies zu zeigen, muss zunächst gezeigt werden, dass wenn das
zugrundeliegende lineare
Modell ein von Null verschiedenes Absolutglied
enthält, der empirische Mittelwert der Schätzwerte
mit dem der beobachteten Messwerte
übereinstimmt. Dies gilt, wegen

und daher
 ,
,
wobei der letzte Schritt aus der Tatsache folgt, dass sich
auch schreiben lässt als:
 .
.
Durch die Quadratsummenzerlegung
 bzw.
bzw.  kann man durch ersetzen von
in
auf diesem Wege ebenfalls die Folgende Darstellung für die Residuenquadratsumme
finden:
kann man durch ersetzen von
in
auf diesem Wege ebenfalls die Folgende Darstellung für die Residuenquadratsumme
finden:
 .
.
Matrixschreibweise
In Matrixschreibweise kann die erklärte Quadratsumme wie folgt ausgedrückt werden
 .
.
Hierbei ist  ein Vektor mit
den Elementen
ein Vektor mit
den Elementen  und
und  ist definiert durch
ist definiert durch  ,
wobei
,
wobei  den Kleinste-Quadrate-Schätzvektor
und
den Kleinste-Quadrate-Schätzvektor
und  die Datenmatrix darstellt.
die Datenmatrix darstellt.
Literatur
- Moosmüller, Gertrud. Methoden der empirischen Wirtschaftsforschung. Pearson Deutschland GmbH, 2008.
- Ludwig Fahrmeir, Rita Künstler, Iris Pigeot, Gerhard Tutz: Statistik. Der Weg zur Datenanalyse. 8., überarb. und erg. Auflage. Springer Spektrum, Berlin/ Heidelberg 2016, ISBN 978-3-662-50371-3.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 23.10. 2022