Ordnungsstatistik
In der Statistik bezeichnet die
 -te
Ordnungsstatistik (auch Ordnungsgröße genannt)
den -kleinsten
Wert einer Stichprobe.
Ordnungsstatistiken sind damit spezielle Zufallsvariablen.
Sie werden aus einer vorgegebenen Gruppe von Zufallsvariablen gewonnen und
modifizieren diese so, dass die Realisierungen
der Ordnungsstatistik den Realisierungen der zugrunde liegenden Zufallsvariablen
entsprechen, aber immer der Größe nach geordnet sind.
-te
Ordnungsstatistik (auch Ordnungsgröße genannt)
den -kleinsten
Wert einer Stichprobe.
Ordnungsstatistiken sind damit spezielle Zufallsvariablen.
Sie werden aus einer vorgegebenen Gruppe von Zufallsvariablen gewonnen und
modifizieren diese so, dass die Realisierungen
der Ordnungsstatistik den Realisierungen der zugrunde liegenden Zufallsvariablen
entsprechen, aber immer der Größe nach geordnet sind.
Daher treten Ordnungsstatistiken insbesondere bei der Untersuchung von zufälligen Strukturen auf, die mit einer Ordnung versehen sind. Dazu zählt beispielsweise die Analyse von Wartezeitprozessen oder die Bestimmung von Schätzfunktionen für den Median oder Quantile.
Definition
Gegeben seien Zufallsvariablen  .
Sind die Zufallsvariablen bindungsfrei, nehmen also fast
sicher nicht denselben Wert an, formell ausgedrückt
.
Sind die Zufallsvariablen bindungsfrei, nehmen also fast
sicher nicht denselben Wert an, formell ausgedrückt
 ,
,
so definiert man

und

für  .
Dann heißen
.
Dann heißen  die Ordnungsstatistiken von .
Die Zufallsvariable
die Ordnungsstatistiken von .
Die Zufallsvariable  wird dann auch die
wird dann auch die  -te
Ordnungsstatistik genannt. Als alternative Notation wird auch
-te
Ordnungsstatistik genannt. Als alternative Notation wird auch  anstelle von
verwendet.
anstelle von
verwendet.
Sind die Zufallsvariablen nicht bindungsfrei, so lassen sich die Ordnungsstatistiken definieren als
 .
.
Hierbei bezeichnet  die Indikatorfunktion
auf der Menge
die Indikatorfunktion
auf der Menge  .
Im bindungsfreien Fall stimmen beide Definitionen überein. Nicht alle Autoren
fordern wie oben, dass die Zufallsvariablen fast sicher ungleiche Werte
annehmen. Die Eigenschaften der Ordnungsstatistiken variieren dann leicht.
.
Im bindungsfreien Fall stimmen beide Definitionen überein. Nicht alle Autoren
fordern wie oben, dass die Zufallsvariablen fast sicher ungleiche Werte
annehmen. Die Eigenschaften der Ordnungsstatistiken variieren dann leicht.
Eigenschaften
Fordert man in der Definition
 für alle ,
für alle ,
so gilt

Äquivalent dazu gilt für die Realisierungen
 für fast alle Ereignisse
für fast alle Ereignisse
 .
.
Die Realisierungen der Ordnungsstatistiken sind also (fast sicher) strikt aufsteigend.
Verzichtet man auf die Forderung, dass die Zufallsvariablen fast sicher nicht dieselben Werte annehmen sollen, so gilt entsprechend

Die Realisierungen sind dann nur noch (fast sicher) aufsteigend.
Verteilung der Ordnungsstatistiken
Für die Verteilungsfunktion
der -ten
Ordnungsstatistik gilt
![{\displaystyle F_{X_{i:n}}(y)=\sum _{j=i}^{n}{\binom {n}{j}}F(y)^{j}\left[1-F(y)\right]^{n-j},\quad y\in \mathbb {R} ,\ 1\leq i\leq n,\ F=F_{X}.}](/svg/06409beb00f32368439202d6278468b6b3a582e3.svg)
Wichtige Spezialfälle der Verteilung ergeben sich für das Minimum ( )
und Maximum (
)
und Maximum ( )
als
)
als
![{\displaystyle F_{X_{1:n}}(y)=1-\left[1-F(y)\right]^{n}{\text{ bzw.}}}](/svg/69b5510c36dffdddc240db34210a37af4423abd0.svg)
![{\displaystyle F_{X_{n:n}}(y)=\left[F(y)\right]^{n}.}](/svg/6a6a3f1c82fd43c4c069860c627dbde9f3fa6336.svg)
Hat die Verteilung von  eine Dichtefunktion
eine Dichtefunktion
 ,
dann erhält man durch Differenzieren die Dichtefunktion
,
dann erhält man durch Differenzieren die Dichtefunktion
![{\displaystyle f_{X_{i:n}}(y)={\frac {n!}{(i-1)!(n-i)!}}f_{X}(y)\left[F_{X}(y)\right]^{i-1}\left[1-F_{X}(y)\right]^{n-i}}](/svg/c6914f0a3adcbfc309e5049cff9b9350a61278ed.svg)
der -ten
Ordnungsstatistik.
Anwendung
In der nichtparametrischen Statistik lassen sich Rangstatistiken oder empirische Verteilungsfunktionen durch Ordnungsstatistiken ausdrücken. Zudem können aus Ordnungsstatistiken schwach konsistente Schätzer für Quantile abgeleitet werden. Weiter lassen sich durch oben genannte Verteilung über Faltungen und Transformationssätze die Verteilung von wichtigen Maßzahlen wie dem Median oder der Spannweite gewinnen.
Beispiel
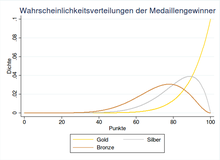
Es wird das Finale eines Wettbewerbs der Leichtathletik, bestehend aus den
besten  Teilnehmern, ausgetragen. In diesem Beispiel wird angenommen, dass die
Leistungsdichte im Finale des Wettkampfes sehr groß ist und es daher keine
Favoriten für die Medaillen gibt. Für die zufällige Gesamtpunktzahl jedes
Athleten wird daher dieselbe stetige Gleichverteilung im Punktebereich von
Teilnehmern, ausgetragen. In diesem Beispiel wird angenommen, dass die
Leistungsdichte im Finale des Wettkampfes sehr groß ist und es daher keine
Favoriten für die Medaillen gibt. Für die zufällige Gesamtpunktzahl jedes
Athleten wird daher dieselbe stetige Gleichverteilung im Punktebereich von  bis
bis  angenommen. Es entscheidet demnach ausschließlich die Tagesform über die
Gesamtpunktzahl, welche starken Schwankungen unterliegt, und alle Athleten
besitzen das gleiche Leistungspotential. Setzt man die Dichtefunktion
angenommen. Es entscheidet demnach ausschließlich die Tagesform über die
Gesamtpunktzahl, welche starken Schwankungen unterliegt, und alle Athleten
besitzen das gleiche Leistungspotential. Setzt man die Dichtefunktion ![{\displaystyle f_{X}(x)={\frac {1}{100}}\cdot I_{[0,100]}(x)}](/svg/c7646fc7f7b9e99283a3128fbca4f822c44401d6.svg) und die Verteilungsfunktion
und die Verteilungsfunktion
![{\displaystyle F_{X}(x)={\begin{cases}0&x<0\\{\frac {x}{100}}\cdot I_{[0,100]}(x)&0\leq x\leq 100\\1&x>100\end{cases}}}](/svg/81e06d55f119c0c089b8ec11eb1d987ac58f2b57.svg)
der stetigen Gleichverteilung in die obige Dichtefunktion der
Ordnungsstatistik ein, erhält man die Verteilungen für die einzelnen Ränge. Da
die Punktzahlen in der Ordnungsstatistik aufsteigend sortiert sind, erhält man
für  die Wahrscheinlichkeitsverteilung für die Goldmedaille, für
die Wahrscheinlichkeitsverteilung für die Goldmedaille, für  die der Silbermedaille und für
die der Silbermedaille und für  die der Bronzemedaille. Der nebenstehenden Grafik ist bereits zu entnehmen, dass
für die Goldmedaille eine höhere Punktzahl zu erwarten ist als für die Silber-
oder Bronzemedaille. Da die Punkte in diesem Beispiel als stetige
Gleichverteilung modelliert wurden, ist die -te
Ordnungsstatistik für
die der Bronzemedaille. Der nebenstehenden Grafik ist bereits zu entnehmen, dass
für die Goldmedaille eine höhere Punktzahl zu erwarten ist als für die Silber-
oder Bronzemedaille. Da die Punkte in diesem Beispiel als stetige
Gleichverteilung modelliert wurden, ist die -te
Ordnungsstatistik für  (siehe Grafik) jeweils Beta-verteilt
(multipliziert mit )
mit den Parametern
und
(siehe Grafik) jeweils Beta-verteilt
(multipliziert mit )
mit den Parametern
und  .
Der Erwartungswert einer solchen Betaverteilung ist
.
Der Erwartungswert einer solchen Betaverteilung ist  .
Für die Goldmedaille ist daher eine Punktzahl von
.
Für die Goldmedaille ist daher eine Punktzahl von  ,
für Silber
,
für Silber  und für Bronze
und für Bronze  zu erwarten. Falls ein Athlet bereits
zu erwarten. Falls ein Athlet bereits  Punkte erhalten hat und auf die Punktzahlen der anderen Sportler wartet, kann er
unter den gemachten Annahmen seine eigenen Chancen für Gold berechnen. Die
Wahrscheinlichkeit, dass die
Punkte erhalten hat und auf die Punktzahlen der anderen Sportler wartet, kann er
unter den gemachten Annahmen seine eigenen Chancen für Gold berechnen. Die
Wahrscheinlichkeit, dass die  anderen Athleten alle schlechter abschneiden, beträgt
anderen Athleten alle schlechter abschneiden, beträgt  .
Falls der Athlet insgesamt
Punkte erhält, wie für die Goldmedaille erwartet, wird er also trotzdem nur mit
einer Wahrscheinlichkeit von
.
Falls der Athlet insgesamt
Punkte erhält, wie für die Goldmedaille erwartet, wird er also trotzdem nur mit
einer Wahrscheinlichkeit von  die Goldmedaille bekommen.
die Goldmedaille bekommen.
Literatur
- Herbert Büning und Götz Trenkler: Nichtparametrische statistische Methoden. 2. Auflage, de Gruyter, Berlin und New York 1994, ISBN 3-11-016351-9


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 03.02. 2022