IPv6
| Anwendung | HTTP | IMAP | SMTP | DNS | … |
| Transport | TCP | UDP | |||
| Internet | IPv6 | ||||
| Netzzugang | Ethernet | Token Bus |
Token Ring |
FDDI | … |
Das Internet Protocol Version 6 (IPv6), früher auch Internet Protocol next Generation (IPng) genannt, ist ein von der Internet Engineering Task Force (IETF) seit 1998 standardisiertes Verfahren zur Übertragung von Daten in paketvermittelnden Rechnernetzen, insbesondere dem Internet. In diesen Netzen werden die Daten in Paketen versendet, in welchen nach einem Schichtenmodell Steuerinformationen verschiedener Netzwerkprotokolle ineinander verschachtelt um die eigentlichen Nutzdaten herum übertragen werden. IPv6 stellt als Protokoll der Vermittlungsschicht (Schicht 3 des OSI-Modells) im Rahmen der Internetprotokollfamilie eine über Teilnetze hinweg gültige 128-Bit-Adressierung der beteiligten Netzwerkelemente (Rechner oder Router) her. Ferner regelt es unter Verwendung dieser Adressen den Vorgang der Paketweiterleitung zwischen Teilnetzen (Routing). Die Teilnetze können so mit verschiedenen Protokollen unterer Schichten betrieben werden, die deren unterschiedlichen physikalischen und administrativen Gegebenheiten Rechnung tragen.
Im Internet soll IPv6 im Laufe der Zeit die Version 4 des Internet Protocols vollständig ablösen, da es eine deutlich größere Zahl möglicher Adressen bietet, die bei IPv4 zu erschöpfen drohen. Kritiker befürchten ein Zurückdrängen der Anonymität im Internet durch die nun mögliche zeitlich stabilere und weiter reichende öffentliche Adressierung. Befürworter bemängeln die zögerliche Einführung von IPv6 angesichts der ausgelaufenen IPv4-Adressvergabe in allen Kontinenten bis auf Afrika. Zugriffe auf Google von Nutzern aus Deutschland verwendeten im April 2022 IPv6 zu etwa 60 %.
Gründe für ein neues Internet-Protokoll
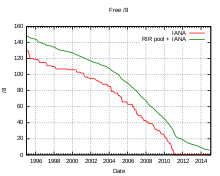
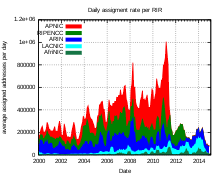
IPv4 bietet theoretisch einen Adressraum von etwas über vier Milliarden IP-Adressen (232 = 2564 = 4.294.967.296), der von der IANA in 256 /8-Netze eingeteilt wird, wovon 221 weitgehend zur Nutzung freigegeben, also beispielsweise an RIRs zugewiesen wurden. Die restlichen 35 /8-Netze wurden für spezielle Zwecke (z.B. 127/8 für Loopback) oder für die Zukunft reserviert, was den verfügbaren Bereich rechnerisch auf 3.707.764.736 reduziert. Nachdem jedoch auch einige Unterbereiche (wie 100.64.0.0/10) der an sich freigegebenen /8-Netze für andere Zwecke reserviert wurden, reduziert sich dieser Bestand um weitere 5.506.830 IP-Adressen, sodass der tatsächlich nutzbare Adressbereich, um z.B. Computer und andere Geräte direkt anzusprechen, letztlich auf 3.702.257.906 IP-Adressen sinkt. In den Anfangstagen des Internets, als es nur wenige Rechner gab, die eine IP-Adresse brauchten, war dies vollkommen ausreichend. Man hatte sogar größere Adressbereiche u.a. für große Organisationen reserviert, wodurch noch weniger freie Adressen für Privatpersonen übrig blieben.
Im Laufe der Zeit erlangte aber das Internet immer größere Verbreitung und die Weltbevölkerung war lange schon größer als die Zahl verfügbarer IPv4-Adressen. Hinzu kam, dass unter anderem eine Website bereits dauerhaft eine oder mehrere Adressen belegt. Es brauchte also ein besseres System, das ohne technische Provisorien viel mehr Adressen bereitstellt. Weitere Informationen siehe Adressknappheit von IPv4.
Durch eine kurzsichtige Vergabepraxis gibt es im IPv4-Adressraum eine starke Fragmentierung. Bei IPv6 hingegen wurde eine weitsichtigere Praxis angewandt.
Aus diesen Gründen begann die IETF
bereits 1995 die Arbeiten an IPv6. Im Dezember 1998 wurde IPv6 mit der
Publikation von  RFC 2460 auf dem Standards
Track offiziell zum Nachfolger von IPv4 gekürt. Im Juli 2017
veröffentlichte die IETF
RFC 2460 auf dem Standards
Track offiziell zum Nachfolger von IPv4 gekürt. Im Juli 2017
veröffentlichte die IETF ![]() RFC 8200, der die ursprüngliche Fassung ersetzt.
RFC 8200, der die ursprüngliche Fassung ersetzt.
Die wesentlichen neuen Eigenschaften von IPv6 umfassen:
- Vergrößerung des Adressraums von IPv4 mit 232 (≈ 4,3 Milliarden = 4,3·109) Adressen auf 2128 (≈ 340 Sextillionen = 3,4·1038) Adressen bei IPv6, d.h. Vergrößerung um den Faktor 296 (≈ 7,9·1028).
- Vereinfachung und Verbesserung des Protokollrahmens (Kopfdaten); dies entlastet Router von Rechenaufwand.
- zustandslose automatische Konfiguration von IPv6-Adressen; zustandsbehaftete Verfahren wie DHCP werden beim Einsatz von IPv6 damit in vielen Anwendungsfällen überflüssig
- Mobile IP sowie Vereinfachung von Umnummerierung und Multihoming
- Implementierung von IPsec innerhalb des IPv6-Standards. Dadurch wird die Verschlüsselung und die Überprüfung der Authentizität von IP-Paketen ermöglicht.
- Unterstützung von Netztechniken wie Quality of Service und Multicast
Die hauptsächliche Motivation zur Vergrößerung des Adressraums besteht in der Wahrung des Ende-zu-Ende-Prinzips, das ein zentrales Designprinzip des Internets ist: Nur die Endknoten des Netzes sollen aktive Protokolloperationen ausführen, das Netz zwischen den Endknoten ist nur für die Weiterleitung der Datenpakete zuständig. (Das Internet unterscheidet sich hier wesentlich von anderen digitalen Datenübertragungsnetzwerken wie z.B. GSM.) Dazu ist es notwendig, dass jeder Netzknoten global eindeutig adressierbar ist.
Heute übliche Verfahren wie Network Address Translation (NAT), welche derzeit die IPv4-Adressknappheit umgehen, verletzen das Ende-zu-Ende-Prinzip. Sie ermöglichen den so angebundenen Rechnern nur, ausgehende Verbindungen aufzubauen. Aus dem Internet können diese hingegen nicht ohne Weiteres kontaktiert werden. Auch verlassen sich IPsec oder Protokolle auf höheren Schichten wie z.B. FTP und SIP teilweise auf das Ende-zu-Ende-Prinzip und sind mit NAT nur eingeschränkt oder mittels Zusatzlösungen funktionsfähig.
Besonders für Heimanwender bedeutet IPv6 damit einen Paradigmenwechsel: Anstatt vom Provider nur eine einzige IP-Adresse zugewiesen zu bekommen und über NAT mehrere Geräte ans Internet anzubinden, bekommt man den global eindeutigen IP-Adressraum für ein ganzes Teilnetz zur Verfügung gestellt, so dass jedes seiner Geräte eine IP-Adresse aus diesem erhalten kann. Damit wird es für Endbenutzer einfacher, durch das Anbieten von Diensten aktiv am Netz teilzunehmen. Zudem entfallen die Probleme, die bei NAT durch die Adressumschreibung entstehen.
Bei der Wahl der Adresslänge und damit der Größe des zur Verfügung stehenden Adressraums waren mehrere Faktoren zu berücksichtigen. Zum einen müssen pro Datenpaket auch Quell- und Ziel-IP-Adresse übertragen werden. Längere IP-Adressen führen damit zu erhöhtem Protokoll-Overhead, d.h. das Verhältnis zwischen tatsächlichen Nutzdaten und der zur Vermittlung notwendigen Protokolldaten sinkt. Auf der anderen Seite sollte dem zukünftigen Wachstum des Internets Rechnung getragen werden. Zudem sollte es zur Verhinderung der Fragmentierung des Adressraums möglich sein, einer Organisation nur ein einziges Mal Adressraum zuweisen zu müssen. Um den Prozess der Autokonfiguration sowie Umnummerierung und Multihoming zu vereinfachen, war es außerdem wünschenswert, einen festen Teil der Adresse zur netzunabhängigen eindeutigen Identifikation eines Netzknotens zu reservieren. Die letzten 64 Bit der Adresse bestehen daher in der Regel aus der EUI-64 der Netzwerkschnittstelle des Knotens.
Adressaufbau von IPv6
IPv6-Adressen sind 128 Bit lang (IPv4: 32 Bit). Die ersten 64 Bit bilden das sogenannte Präfix, die letzten 6 Bit bilden bis auf Sonderfälle einen für die Netzwerkschnittstelle (englisch network interface) eindeutigen Interface-Identifier. Eine Netzwerkschnittstelle kann unter mehreren IP-Adressen erreichbar sein; in der Regel ist sie dies mittels ihrer link-lokalen Adresse und einer global eindeutigen Adresse. Derselbe Interface-Identifier kann damit Teil mehrerer IPv6-Adressen sein, welche mit verschiedenen Präfixen auf dieselbe Netzwerkschnittstelle gebunden sind. Insbesondere gilt dies auch für Präfixe möglicherweise unterschiedlicher Internetanbieter; dies vereinfacht Multihoming-Verfahren.
Da die Erzeugung des Interface-Identifiers aus der global eindeutigen
MAC-Adresse die
Nachverfolgung von Benutzern ermöglicht, wurden die Privacy-Extensions
(PEX, ![]() RFC 4941) entwickelt, um diese permanente Kopplung der
Benutzeridentität an die IPv6-Adressen aufzuheben. Indem der
Interface-Identifier zufällig generiert und regelmäßig gewechselt wird, soll ein
Teil der Anonymität von IPv4 wiederhergestellt werden.
RFC 4941) entwickelt, um diese permanente Kopplung der
Benutzeridentität an die IPv6-Adressen aufzuheben. Indem der
Interface-Identifier zufällig generiert und regelmäßig gewechselt wird, soll ein
Teil der Anonymität von IPv4 wiederhergestellt werden.
Da im Privatbereich in der IPv6-Adresse aber sowohl der Interface-Identifier als auch das Präfix allein recht sicher auf einen Nutzer schließen lassen können, ist aus Datenschutzgründen in Verbindung mit den Privacy Extensions ein vom Provider dynamisch zugewiesenes, z.B. täglich wechselndes Präfix wünschenswert. (Mit einer statischen Adresszuteilung geht in der Regel insbesondere ein Eintrag in der öffentlichen Whois-Datenbank einher.) Dabei ist es wie oben beschrieben grundsätzlich möglich, auf derselben Netzwerkschnittstelle sowohl IPv6-Adressen aus dynamischen als auch aus fest zugewiesenen Präfixen parallel zu verwenden. In Deutschland hat der Deutsche IPv6-Rat Datenschutzleitlinien formuliert, die auch eine dynamische Zuweisung von IPv6-Präfixen vorsehen.
Adressnotation
Die textuelle Notation von IPv6-Adressen ist in Abschnitt 2.2 von ![]() RFC 4291
beschrieben:
RFC 4291
beschrieben:
- IPv6-Adressen werden für gewöhnlich hexadezimal
(IPv4: dezimal)
notiert, wobei die Zahl in acht Blöcke zu jeweils 16 Bit (4
Hexadezimalstellen) unterteilt wird. Diese Blöcke werden durch Doppelpunkte
(IPv4: Punkte) getrennt notiert:
2001:0db8:85a3:08d3:1319:8a2e:0370:7344. - Führende Nullen innerhalb eines Blockes dürfen ausgelassen werden:
2001:0db8:0000:08d3:0000:8a2e:0070:7344ist gleichbedeutend mit2001:db8:0:8d3:0:8a2e:70:7344. - Ein oder mehrere aufeinander folgende Blöcke, deren Wert 0 (bzw.
0000) beträgt, dürfen ausgelassen werden. Dies wird durch zwei
aufeinander folgende Doppelpunkte angezeigt:
2001:db8:0:0:0:0:1428:57abist gleichbedeutend mit2001:db8::1428:57ab. - Die Reduktion durch Regel 3 darf nur einmal durchgeführt werden, das
heißt, es darf höchstens eine zusammenhängende Gruppe aus Null-Blöcken in der
Adresse ersetzt werden. Die Adresse
2001:0db8:0:0:8d3:0:0:0darf demnach entweder zu2001:db8:0:0:8d3::oder2001:db8::8d3:0:0:0gekürzt werden;2001:db8::8d3::ist unzulässig, da dies mehrdeutig ist und fälschlicherweise z.B. auch als2001:db8:0:0:0:8d3:0:0interpretiert werden könnte. Die Reduktion darf auch dann nicht mehrfach durchgeführt werden, wenn das Ergebnis eindeutig wäre, weil jeweils genau eine einzige 0 gekürzt wurde. Es empfiehlt sich, die Gruppe mit den meisten Null-Blöcken zu kürzen. - Ebenfalls darf für die letzten beiden Blöcke (vier Bytes, also 32 Bits) der
Adresse die herkömmliche dezimale Notation mit Punkten als Trennzeichen
verwendet werden. So ist
::ffff:127.0.0.1eine alternative Schreibweise für::ffff:7f00:1. Diese Schreibweise wird vor allem bei Einbettung des IPv4-Adressraums in den IPv6-Adressraum verwendet.
URL-Notation von IPv6-Adressen
In einer URL wird die IPv6-Adresse in eckige Klammern eingeschlossen, z.B.:
http://[2001:0db8:85a3:08d3::0370:7344]/
Diese Notation verhindert die fälschliche Interpretation von Portnummern als Teil der IPv6-Adresse:
http://[2001:0db8:85a3:08d3::0370:7344]:8080/
Netznotation
IPv6-Netzwerke werden in der CIDR-Notation
aufgeschrieben. Dazu werden die erste Adresse (bzw. die Netzadresse) und die
Länge des Präfixes in Bits getrennt durch einen Schrägstrich notiert. Zum
Beispiel steht 2001:0db8:1234::/48 für das Netzwerk mit den
Adressen 2001:0db8:1234:0000:0000:0000:0000:0000 bis
2001:0db8:1234:ffff:ffff:ffff:ffff:ffff. Die Größe eines
IPv6-Netzes (oder Subnetzes) im Sinne der Anzahl der vergebbaren Adressen in
diesem Netz muss also eine Zweierpotenz sein. Da ein einzelner
Host
auch als Netzwerk mit einem 128 Bit langen Präfix betrachtet werden kann,
werden Host-Adressen manchmal mit einem angehängten „/128“ geschrieben.
Aufteilung des IPv6-Adressraums
Adresszuweisung
Typischerweise bekommt ein Internetprovider (ISP) die ersten 32 Bit (oder weniger) als Netz von einer Regional Internet Registry (RIR) zugewiesen. Dieser Bereich wird vom Provider weiter in Subnetze aufgeteilt. Die Länge der Zuteilung an Endkunden wird dabei dem ISP überlassen; vorgeschrieben ist die minimale Zuteilung eines /64-Netzes. Ältere Dokumente (z.B. RFC 3177) schlagen eine Zuteilung von /48-Netzen an Endkunden vor; in Ausnahmefällen ist die Zuteilung größerer Netze als /48 oder mehrerer /48-Netze an einen Endkunden möglich. Informationen über die Vergabe von IPv6-Netzen können über die Whois-Dienste der jeweiligen RIRs abgefragt werden. Es gibt in deren RPSL-Datenbanken dazu inet6num- und route6-Objekte und in vielen anderen Objekttypen Attribute zur Multi-Protocol-Erweiterung (mp) mit Angabe der Address-Family (afi) zum Spezifizieren des neuen Protokolls.
Einem einzelnen Netzsegment
wird in der Regel ein 64 Bit langes Präfix zugewiesen, das dann zusammen
mit einem 64 Bit langen Interface-Identifier die Adresse bildet. Der
Interface-Identifier kann entweder aus der MAC-Adresse
der Netzwerkschnittstelle erstellt oder anders eindeutig zugewiesen werden; das
genaue Verfahren ist in ![]() RFC 4291, Anhang A beschrieben.
RFC 4291, Anhang A beschrieben.
Hat z.B. ein Netzwerkgerät die IPv6-Adresse
2001:0db8:85a3:08d3:1319:8a2e:0370:7347/64,
so lautet das Präfix
- 2001:0db8:85a3:08d3::/64
und der Interface-Identifier
- 1319:8a2e:0370:7347.
Der Provider bekam von der RIR wahrscheinlich das Netz
- 2001:0db8::/32
zugewiesen und der Endkunde vom Provider möglicherweise das Netz
- 2001:0db8:85a3::/48,
oder aber nur
- 2001:0db8:85a3:0800::/56.
Adressbereiche
Es gibt verschiedene IPv6-Adressbereiche mit Sonderaufgaben und
unterschiedlichen Eigenschaften. Diese werden meist schon durch die ersten Bits
der Adresse signalisiert. Sofern nicht weiter angegeben, werden die Bereiche in
![]() RFC 4291 bzw.
RFC 4291 bzw. ![]() RFC 5156 definiert. Unicast-Adressen charakterisieren
Kommunikation eines Netzknotens mit genau einem anderen Netzknoten;
Einer-zu-vielen-Kommunikation wird durch Multicast-Adressen abgebildet.
RFC 5156 definiert. Unicast-Adressen charakterisieren
Kommunikation eines Netzknotens mit genau einem anderen Netzknoten;
Einer-zu-vielen-Kommunikation wird durch Multicast-Adressen abgebildet.
Besondere Adressen
::/128bzw. in der ausgeschriebenen Variante0:0:0:0:0:0:0:0/128, ist die nicht spezifizierte Adresse. Sie darf keinem Host zugewiesen werden, sondern zeigt das Fehlen einer Adresse an. Sie wird beispielsweise von einem initialisierenden Host als Absenderadresse in IPv6-Paketen verwendet, solange er seine eigene Adresse noch nicht mitgeteilt bekommen hat. Jedoch können auch Serverprogramme durch Angabe dieser Adresse bewirken, dass sie auf allen Adressen des Hosts lauschen. Dies entspricht0.0.0.0/32unter IPv4.::/0bzw. in der ausgeschriebenen Variante0:0:0:0:0:0:0:0/0bezeichnet die Standard-Route (default route), die verwendet wird, wenn in der Routingtabelle kein Eintrag gefunden wird. Dies entspricht0.0.0.0/0unter IPv4.::1/128bzw. in der ausgeschriebenen Variante0:0:0:0:0:0:0:1/128, ist die Adresse des eigenen Standortes (loopback-Adresse, die in der Regel mit localhost verknüpft ist). Unter IPv4 wird zu diesem Zweck fast ausschließlich127.0.0.1/32aus dem Adressraum127.0.0.0–127.255.255.255verwendet, wenngleich dort also nicht nur eine IP-Adresse, sondern ein ganzes /8-Subnetz für das Loopback-Netzwerk reserviert ist.
Link-Local-Unicast-Adressen
Link-Local-Adressen
sind nur innerhalb abgeschlossener Netzwerksegmente gültig. Ein Netzwerksegment
ist ein lokales Netz, gebildet mit Switches
oder Hubs,
bis zum ersten Router. Reserviert ist hierfür der Bereich
„fe80::/10“.
Nach diesen 10 Bits folgen 54 Bits mit dem Wert 0, sodass die
Link-Local-Adressen immer das Präfix „fe80::/64“ haben:
| 10 Bits | 54 Bits | 64 Bits |
|---|---|---|
| 1111111010 | 0 | Interface ID |
Link-Local-Adressen nutzt man zur Adressierung von Knoten in abgeschlossenen
Netzwerksegmenten sowie zur Autokonfiguration oder Neighbour-Discovery. Dadurch
muss man in einem Netzwerksegment keinen DHCP-Server zur automatischen
Adressvergabe konfigurieren. Link-Local-Adressen sind mit APIPA-Adressen im Netz
169.254.0.0/16 vergleichbar.
Soll ein Gerät mittels einer dieser Adressen kommunizieren, so muss die
Zone ID mit angegeben werden, da eine Link-Lokale-Adresse auf einem Gerät
mehrfach vorhanden sein kann. Bei einer einzigen Netzwerkschnittstelle würde
eine Adresse etwa so aussehen: fe80::7645:6de2:ff:1%1 bzw.
fe80::7645:6de2:ff:1%eth0.
Site Local Unicast (veraltet)
fec0::/10 (fec0… bis feff…), auch
standortlokale Adressen (site local addresses), waren die Nachfolger der
privaten
IP-Adressen (beispielsweise 192.168.x.x). Sie durften nur
innerhalb derselben Organisation geroutet werden. Die Wahl des verwendeten
Adressraums innerhalb von fec0::/10 war für eine Organisation
beliebig. Bei der Zusammenlegung von ehemals getrennten Organisationen oder wenn
eine VPN-Verbindung zwischen eigentlich getrennten mit Site Local Addresses
nummerierten Netzwerken hergestellt wurde, konnte es daher zu Überschneidungen
der Adressräume an den unterschiedlichen Standorten kommen. Aus diesem und
weiteren Gründen sind Site Local Addresses nach ![]() RFC 3879 seit
September 2004 überholt (engl. deprecated) und werden aus zukünftigen
Standards verschwinden. Neue Implementierungen müssen diesen Adressbereich als
Global-Unicast-Adressen behandeln. Nachfolger der standortlokalen Adressen sind
die Unique Local Addresses, die im nächsten Abschnitt beschrieben werden.
RFC 3879 seit
September 2004 überholt (engl. deprecated) und werden aus zukünftigen
Standards verschwinden. Neue Implementierungen müssen diesen Adressbereich als
Global-Unicast-Adressen behandeln. Nachfolger der standortlokalen Adressen sind
die Unique Local Addresses, die im nächsten Abschnitt beschrieben werden.
Unique Local Unicast
fc00::/7 (fc00… bis fdff…). Für private
Adressen gibt es die Unique Local Addresses (ULA), beschrieben in ![]() RFC 4193. Derzeit ist nur das Präfix
RFC 4193. Derzeit ist nur das Präfix fd für
lokal generierte ULA vorgesehen. Das Präfix fc ist für global
zugewiesene, eindeutige ULA reserviert. Auf das Präfix folgen dann 40 Bits,
die als eindeutige Site-ID fungieren. Diese Site-ID ist bei den ULA mit dem
Präfix fd zufällig zu generieren und somit
nur sehr wahrscheinlich eindeutig. Bei den global vergebenen ULA jedoch
auf jeden Fall eindeutig (![]() RFC 4193 gibt jedoch keine konkrete Implementierung der
Zuweisung von global eindeutigen Site-IDs an). Nach der Site-ID folgt eine
16-Bit-Subnet-ID, welche ein Netz innerhalb der Site angibt.
RFC 4193 gibt jedoch keine konkrete Implementierung der
Zuweisung von global eindeutigen Site-IDs an). Nach der Site-ID folgt eine
16-Bit-Subnet-ID, welche ein Netz innerhalb der Site angibt.
Eine Beispiel-ULA wäre fd9e:21a7:a92c:2323::1. Hierbei ist
fd das Präfix für lokal generierte ULAs, 9e:21a7:a92c
ein einmalig zufällig erzeugter 40-Bit-Wert und 2323 eine
willkürlich gewählte Subnet-ID.
Die Verwendung von wahrscheinlich eindeutigen Site-IDs hat den Vorteil, dass zum Beispiel beim Einrichten eines Tunnels zwischen getrennt voneinander konfigurierten Netzwerken Adresskollisionen sehr unwahrscheinlich sind. Weiterhin wird erreicht, dass Pakete, welche an eine nicht erreichbare Site gesendet werden, mit großer Wahrscheinlichkeit ins Leere laufen, anstatt an einen lokalen Host gesendet zu werden, der zufällig die gleiche Adresse hat.
Sofern in einem privaten Netz im Dualstack mit IPv4 nur ULA-Adressen verwendet werden, bevorzugt die Mehrheit der Clients bei einer DNS-Auflösung die IPv4-Adresse, auch wenn ein AAAA-Record existiert, da davon auszugehen ist, dass mit einer ULA-Adresse niemals der öffentliche IPv6-Adressraum erreicht werden kann. Dies führt in der Praxis dazu, dass in privaten Netzen (insbesondere beim Einsatz von NAT6) im Dualstack von ULA-Adressen abgeraten wird.
Es existiert ein Internet-Draft, welcher Richtlinien für Registrare (IANA, RIR) beschreibt, konkret deren Betrieb sowie die Adressvergabe-Regeln. Allerdings ist eine derartige „ULA-Central“ noch nicht gegründet.
Sowohl der ![]() RFC 4193 als auch der Internet-Draft sind identisch in Bezug
auf das Adressformat und den oben genannten Generierungs-Algorithmus.
RFC 4193 als auch der Internet-Draft sind identisch in Bezug
auf das Adressformat und den oben genannten Generierungs-Algorithmus.
Multicast
ff00::/8 (ff…) stehen für Multicast-Adressen. Nach
dem Multicast-Präfix folgen 4 Bits für Flags
und 4 Bits für den Gültigkeitsbereich (Scope).
Für die Flags sind zurzeit folgende Kombinationen gültig:
0: Permanent definierte wohlbekannte Multicast-Adressen (von der IANA zugewiesen)1: (T-Bit gesetzt) Transient (vorübergehend) oder dynamisch zugewiesene Multicast-Adressen3: (P-Bit gesetzt, erzwingt das T-Bit) Unicast-Prefix-based Multicast-Adressen ( RFC 3306)7: (R-Bit gesetzt, erzwingt P- und T-Bit) Multicast-Adressen, welche die Adresse des Rendezvous-Points enthalten ( RFC
3956)
Die folgenden Gültigkeitsbereiche sind definiert:
1: interfacelokal, diese Pakete verlassen die Schnittstelle nie. (Loopback)2: link-lokal, werden von Routern grundsätzlich nie weitergeleitet und können deshalb das Subnetz nicht verlassen.4: adminlokal, der kleinste Bereich, dessen Abgrenzung in den Routern speziell administriert werden muss.5: sitelokal, dürfen zwar geroutet werden, jedoch nicht von Border-Routern.8: organisationslokal, die Pakete dürfen auch von Border-Routern weitergeleitet werden, bleiben jedoch „im Unternehmen“ (hierzu müssen seitens des Routing-Protokolls entsprechende Vorkehrungen getroffen werden).e: globaler Multicast, der überallhin geroutet werden darf.0,3,f: reservierte Bereiche- die restlichen Bereiche sind nicht zugewiesen und dürfen von Administratoren benutzt werden, um weitere Multicast-Regionen zu definieren.
Beispiele für wohlbekannte Multicast-Adressen:
ff01::1,ff02::1: All Nodes Adressen. Entspricht dem Broadcast.ff01::2,ff02::2,ff05::2: All Routers Adressen, adressiert alle Router in einem Bereich.
Global Unicast
Alle anderen Adressen gelten als Global-Unicast-Adressen. Von diesen sind jedoch bisher nur die folgenden Bereiche zugewiesen:
::/96(96 0-Bits) stand für IPv4-Kompatibilitätsadressen, welche in den letzten 32 Bits die IPv4-Adresse enthielten (dies galt nur für globale IPv4 Unicast-Adressen). Diese waren für den Übergang definiert, jedoch im RFC 4291 vom Februar 2006 für überholt (engl.
deprecated) erklärt.0:0:0:0:0:ffff::/96(80 0-Bits, gefolgt von 16 1-Bits) steht für IPv4 mapped (abgebildete) IPv6 Adressen. Die letzten 32 Bits enthalten die IPv4-Adresse. Ein geeigneter Router kann diese Pakete zwischen IPv4 und IPv6 konvertieren und so die neue mit der alten Welt verbinden.2000::/3(2000…bis3fff…; was dem binären Präfix 001 entspricht) stehen für die von der IANA vergebenen globalen Unicast-Adressen, also routbare und weltweit einzigartige Adressen.
-
2001-Adressen werden an Provider vergeben, die diese an ihre Kunden weiterverteilen.
-
- Adressen aus
2001::/32(also beginnend mit2001:0:) werden für den Tunnelmechanismus Teredo benutzt. - Adressen aus
2001:db8::/32dienen Dokumentationszwecken, wie beispielsweise in diesem Artikel, und bezeichnen keine tatsächlichen Netzteilnehmer.
- Adressen aus
2002-Präfixe deuten auf Adressen des Tunnelmechanismus 6to4 hin.- Auch mit
2003,240,260,261,262,280,2a0,2b0und2c0beginnende Adressen werden von Regional Internet Registries (RIRs) vergeben; diese Adressbereiche sind ihnen z.T. aber noch nicht zu dem Anteil zugeteilt, wie dies bei2001::/16der Fall ist. 3ffe::/16-Adressen wurden für das Testnetzwerk 6Bone benutzt; dieser Adressbereich wurde gemäß RFC 3701 wieder an die IANA
zurückgegeben.
64:ff9b::/96kann für den Übersetzungsmechanismus NAT64 gemäß RFC 6146
verwendet werden.
Funktionalität
Autokonfiguration
Mittels Stateless Address Autoconfiguration (SLAAC, zustandslose
Adressenautokonfiguration, spezifiziert in ![]() RFC 4862) kann ein
Host vollautomatisch eine funktionsfähige Internetverbindung aufbauen. Dazu
kommuniziert er mit den für sein Netzwerksegment
zuständigen Routern, um die notwendige
Konfiguration zu ermitteln.
RFC 4862) kann ein
Host vollautomatisch eine funktionsfähige Internetverbindung aufbauen. Dazu
kommuniziert er mit den für sein Netzwerksegment
zuständigen Routern, um die notwendige
Konfiguration zu ermitteln.
Ablauf
Zur initialen Kommunikation mit dem Router weist sich der Host eine link-lokale
Adresse zu, die im Falle einer Ethernet-Schnittstelle
etwa aus deren Hardware-Adresse berechnet werden kann. Damit kann ein Gerät sich
mittels des Neighbor
Discovery Protocols (NDP, siehe auch ICMPv6-Funktionalität)
auf die Suche nach den Routern in seinem Netzwerksegment machen. Dies geschieht
durch eine Anfrage an die Multicast-Adresse
ff02::2, über die alle Router eines Segments erreichbar sind
(Router Solicitation).
Ein Router versendet auf eine solche Anfrage hin Information zu verfügbaren Präfixen, also Information über die Adressbereiche, aus denen ein Gerät sich selbst Unicast-Adressen zuweisen darf. Die Pakete, die diese Informationen tragen, werden Router Advertisements genannt. Sie besitzen ICMPv6-Typ 134 (0x86) und besitzen Informationen über die Lifetime, die MTU und das Präfix des Netzwerks. An ein solches Präfix hängt der Host den auch für die link-lokale Adresse verwendeten Interface-Identifier an.
Um die doppelte Vergabe einer Adresse zu verhindern, ist der Mechanismus Duplicate Address Detection (DAD – Erkennung doppelt vergebener Adressen) vorgesehen. Ein Gerät darf bei der Autokonfiguration nur unvergebene Adressen auswählen. Der DAD-Vorgang läuft ebenfalls ohne Benutzereingriff via NDP ab.
Gültigkeitsangaben
Router können bei der Vergabe von Adresspräfixen begrenzte Gültigkeitszeiten mitgeben: Valid Lifetime und Preferred Lifetime. Innerhalb der Valid Lifetime darf das angegebene Präfix zur Kommunikation verwendet werden; innerhalb der Preferred Lifetime soll dieses Präfix einem anderen, dessen Preferred Lifetime schon abgelaufen ist (dessen Valid Lifetime aber noch nicht), vorgezogen werden. Router verschicken regelmäßig Router Advertisements an alle Hosts in einem Netzsegment, für das sie zuständig sind, mittels derer die Präfix-Gültigkeitszeiten aufgefrischt werden; durch Änderung der Advertisements können Hosts umnummeriert werden. Sind die Router Advertisements nicht über IPsec authentifiziert, ist die Herabsetzung der Gültigkeitszeit eines einem Host bereits bekannten Präfixes auf unter zwei Stunden jedoch nicht möglich.
Verhältnis von Autokonfiguration zu DHCPv6
Die IPv6-Autokonfiguration unterscheidet sich konzeptionell von
DHCP
beziehungsweise DHCPv6.
Während bei der Adressvergabe durch DHCPv6 (definiert in ![]() RFC 3315) von
„Stateful Address Configuration“ gesprochen wird (sinngemäß:
protokollierte Adressvergabe, etwa durch einen DHCP-Server), ist die
Autokonfiguration eine „Stateless Address (Auto)Configuration“, da Geräte
sich selbst eine Adresse zuweisen und diese Vergabe nicht protokolliert wird.
RFC 3315) von
„Stateful Address Configuration“ gesprochen wird (sinngemäß:
protokollierte Adressvergabe, etwa durch einen DHCP-Server), ist die
Autokonfiguration eine „Stateless Address (Auto)Configuration“, da Geräte
sich selbst eine Adresse zuweisen und diese Vergabe nicht protokolliert wird.
Mittels der Autokonfiguration können an Clients keine Informationen zu Host-,
Domainnamen, DNS, NTP-Server
etc. mitgeteilt werden, sofern diese nicht spezifische Erweiterungen von NDP
unterstützen. Als Alternative hat sich der zusätzliche Einsatz eines
DHCPv6-Servers etabliert; dieser liefert die gewünschten Zusatzinformationen,
kümmert sich dabei aber nicht um die Adressvergabe. Man spricht in diesem Fall
von Stateless DHCPv6 (vgl. ![]() RFC 3736). Dem Client kann mittels des Managed-Flags
in der Antwort auf eine NDP-Router-Solicitation angezeigt werden, dass er eine
DHCPv6-Anfrage stellen und somit die Zusatzinformationen beziehen soll.
RFC 3736). Dem Client kann mittels des Managed-Flags
in der Antwort auf eine NDP-Router-Solicitation angezeigt werden, dass er eine
DHCPv6-Anfrage stellen und somit die Zusatzinformationen beziehen soll.
Umnummerierung und Multihoming
Unter IPv4 ist die Umnummerierung (Änderung des IP-Adressbereichs) für Netze ab einer gewissen Größe problematisch, auch wenn Mechanismen wie DHCP dabei helfen. Speziell der Übergang von einem Provider zum nächsten ohne ein „hartes“ Umschalten zu einem festen Zeitpunkt ist schwierig, da dies nur dann möglich ist, wenn das Netz für einen gewissen Zeitraum multihomed ist, also ein Netz gleichzeitig von mehr als einem Provider mit Internet-Anbindung und IP-Adressbereichen versorgt wird. Die Umgehung des Umnummerierens unter IPv4 mittels Border Gateway Protocol (BGP) führt zur Fragmentierung des Adressraums. Es geraten also viele, vergleichsweise kleine Netze bis in die Routingtabellen im Kernbereich des Internets, und die Router dort müssen darauf ausgelegt werden.
Der Vorgang der Umnummerierung wurde beim Design von IPv6 hingegen
berücksichtigt, er wird in ![]() RFC 4076 behandelt. Mechanismen wie die
IPv6-Autokonfiguration helfen dabei. Der parallele Betrieb mehrerer
IP-Adressbereiche gestaltet sich unter IPv6 ebenfalls einfacher als unter IPv4,
wie im Abschnitt Adressaufbau
oben beschrieben. In
RFC 4076 behandelt. Mechanismen wie die
IPv6-Autokonfiguration helfen dabei. Der parallele Betrieb mehrerer
IP-Adressbereiche gestaltet sich unter IPv6 ebenfalls einfacher als unter IPv4,
wie im Abschnitt Adressaufbau
oben beschrieben. In ![]() RFC 3484 wird festgelegt, wie die Auswahl der Quell- und
Zieladressen bei der Kommunikation geschehen soll und wie sie beeinflusst werden
kann, wenn nun jeweils mehrere zur Verfügung stehen. Darüber hinaus darf diese
Auswahl auch auf Anwendungsebene oder durch noch zu schaffende, z.B. die
Verbindungsqualität einbeziehende Mechanismen getroffen werden. Das Ziel ist
unter anderem, dem Betreiber eines Netzwerkes den unkomplizierten Wechsel
zwischen Providern oder gar den dauerhaften Parallelbetrieb mehrerer Provider zu
ermöglichen, um damit den Wettbewerb zu fördern, die Ausfallsicherheit zu
erhöhen oder den Datenverkehr auf Leitungen mehrerer Anbieter zu verteilen.
RFC 3484 wird festgelegt, wie die Auswahl der Quell- und
Zieladressen bei der Kommunikation geschehen soll und wie sie beeinflusst werden
kann, wenn nun jeweils mehrere zur Verfügung stehen. Darüber hinaus darf diese
Auswahl auch auf Anwendungsebene oder durch noch zu schaffende, z.B. die
Verbindungsqualität einbeziehende Mechanismen getroffen werden. Das Ziel ist
unter anderem, dem Betreiber eines Netzwerkes den unkomplizierten Wechsel
zwischen Providern oder gar den dauerhaften Parallelbetrieb mehrerer Provider zu
ermöglichen, um damit den Wettbewerb zu fördern, die Ausfallsicherheit zu
erhöhen oder den Datenverkehr auf Leitungen mehrerer Anbieter zu verteilen.
Mobile IPv6
Mobile
IP wurde als Erweiterung des IPv6-Standards unter dem Namen „Mobile IPv6“
(![]() RFC 6275) in IPv6 integriert. Die Kommunikation erfolgt dabei
virtuell immer unabhängig von der aktuellen Position der Knotenpunkte.
Somit erlaubt Mobile IP Endgeräten, überall unter der gleichen IP-Adresse
erreichbar zu sein, beispielsweise im heimischen Netzwerk und auf einer
Konferenz. Normalerweise müssten dazu aufwändig Routing-Tabellen geändert
werden. Mobile IPv6 benutzt stattdessen einen Schatten-Rechner („Home
Agent“), der das Mobilgerät in seinem Heimnetz vertritt. Eingehende Pakete
werden durch diesen Schattenrechner an die momentane Adresse („Care-of-Address“)
des Mobilgeräts getunnelt. Der Home Agent bekommt die aktuelle Care-of-Address
des Mobilgerätes durch „Binding Updates“ mitgeteilt, die das Gerät an den Home
Agent sendet, sobald es eine neue Adresse im besuchten Fremdnetz erhalten hat.
Mobile IP ist auch für IPv4 spezifiziert; im Gegensatz zu dieser Spezifikation
benötigt Mobile IPv6 jedoch keinen Foreign Agent, der im
Fremdnetz die Anwesenheit von Mobilgeräten registriert.
RFC 6275) in IPv6 integriert. Die Kommunikation erfolgt dabei
virtuell immer unabhängig von der aktuellen Position der Knotenpunkte.
Somit erlaubt Mobile IP Endgeräten, überall unter der gleichen IP-Adresse
erreichbar zu sein, beispielsweise im heimischen Netzwerk und auf einer
Konferenz. Normalerweise müssten dazu aufwändig Routing-Tabellen geändert
werden. Mobile IPv6 benutzt stattdessen einen Schatten-Rechner („Home
Agent“), der das Mobilgerät in seinem Heimnetz vertritt. Eingehende Pakete
werden durch diesen Schattenrechner an die momentane Adresse („Care-of-Address“)
des Mobilgeräts getunnelt. Der Home Agent bekommt die aktuelle Care-of-Address
des Mobilgerätes durch „Binding Updates“ mitgeteilt, die das Gerät an den Home
Agent sendet, sobald es eine neue Adresse im besuchten Fremdnetz erhalten hat.
Mobile IP ist auch für IPv4 spezifiziert; im Gegensatz zu dieser Spezifikation
benötigt Mobile IPv6 jedoch keinen Foreign Agent, der im
Fremdnetz die Anwesenheit von Mobilgeräten registriert.
Header-Format
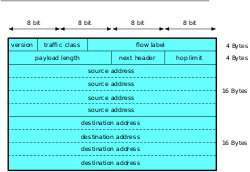
Im Gegensatz zu IPv4 hat der IP-Kopfdatenbereich (Header)
bei IPv6 eine feste Länge von 40 Bytes (320 Bits). Optionale, seltener
benutzte Informationen werden in so genannten Erweiterungs-Kopfdaten (engl.:
Extension Headers) zwischen dem IPv6-Kopfdatenbereich und der
eigentlichen Nutzlast (engl. Payload) eingebettet. Der Kopfdatenbereich
eines IPv6-Paketes setzt sich laut ![]() RFC 2460 aus den folgenden Feldern zusammen:
RFC 2460 aus den folgenden Feldern zusammen:
| Feld | Länge | Inhalt |
|---|---|---|
| Version | 4 Bit | IP-Versionsnummer (6) |
| Traffic Class | 8 Bit | Quality
of Service: Die Bits 0–5 werden für DSCP
verwendet, die Bits 6–7 für ECN.
Laut |
| Flow Label | 20 Bit | Ebenfalls für QoS oder Echtzeitanwendungen verwendeter Wert. Pakete, die dasselbe Flow Label tragen, werden gleich behandelt. |
| Payload Length | 16 Bit | Länge des IPv6-Paketinhaltes (ohne Kopfdatenbereich, aber inklusive der Erweiterungs-Kopfdaten) in Byte |
| Next Header | 8 Bit | Identifiziert den Typ des nächsten Kopfdatenbereiches, dieser kann entweder einen Erweiterungs-Kopfdatenbereich (siehe nächste Tabelle) oder ein Protokoll höherer Schicht (engl.: Upper Layer Protocol) bezeichnen, wie z.B. TCP (Typ 6) oder UDP (Typ 17). |
| Hop Limit | 8 Bit | Maximale Anzahl an Zwischenschritten über Router, die ein Paket zurücklegen darf; wird beim Durchlaufen eines Routers („Hops“) um eins verringert. Pakete mit null als Hop Limit werden verworfen. Es entspricht dem Feld Time to Live (TTL) bei IPv4. |
| Source Address | 128 Bit | Adresse des Senders |
| Destination Address | 128 Bit | Adresse des Empfängers |
Wie im Next Header Feld verwiesen, sind einige Extension Headers und ein Platzhalter definiert:
| Name | Typ | Größe | Beschreibung | RFCs |
|---|---|---|---|---|
| Hop-By-Hop Options | 0 | variabel | Enthält Optionen, die von allen IPv6-Geräten, die das Paket durchläuft, beachtet werden müssen. Wird z.B. für Jumbograms benutzt. | |
| Routing | 43 | variabel | Durch diesen Header kann der Weg des Paketes durch das Netzwerk beeinflusst werden, er wird unter anderem für Mobile IPv6 verwendet. | |
| Fragment | 44 | 64 Bit | In diesem Header können die Parameter einer Fragmentierung festgelegt werden. | |
| Authentication Header (AH) | 51 | variabel | Enthält Daten, welche die Vertraulichkeit des Paketes sicherstellen können (siehe IPsec). | |
| Encapsulating Security Payload (ESP) | 50 | variabel | Enthält Daten zur Verschlüsselung des Paketes (siehe IPsec). | |
| Destination Options | 60 | variabel | Enthält Optionen, die nur vom Zielrechner des Paketes beachtet werden müssen. | |
| Mobility | 135 | variabel | Enthält Daten für Mobile IPv6. | |
| No Next Header | 59 | leer | Dieser Typ ist nur ein Platzhalter, um das Ende eines Header-Stapels anzuzeigen. |
Die meisten IPv6-Pakete sollten ohne Extension Headers auskommen, diese können bis auf den Destination Options Header nur einmal in jedem Paket vorkommen. Befindet sich nämlich ein Routing Extension Header im Paket, so darf davor ein weiterer Destination Options Header stehen. Die Reihenfolge bei einer Verkettung ist bis auf die genannte Ausnahme die der Tabelle. Alle Extension Headers enthalten ein Next-Header-Feld, in dem der nächste Extension Header oder das Upper Layer Protocol genannt wird.
Die Größen dieser Header sind immer Vielfache von 64 Bit, auch sind die meisten Felder der Kopfdatenbereiche auf 64-Bit-Grenzen ausgerichtet, um Speicherzugriffe im Router zu beschleunigen. Außerdem werden (im Gegensatz zu IPv4) keine Prüfsummen mehr über die IP-Kopfdaten berechnet, es wird nur noch die Fehlerkorrektur in den Schichten 2 und 4 genutzt.
Paketgrößen
Die Maximum Transmission Unit (MTU) darf in einem IPv6-Netzwerk 1280 Byte nicht unterschreiten. Somit unterschreitet auch die Path MTU (PMTU) diesen Wert nicht und es können Pakete bis zu dieser Größe garantiert ohne Fragmentierung übertragen werden. Minimale IPv6-Implementierungen verlassen sich auf diesen Fall.
Ein IPv6-fähiger Rechner muss in der Lage sein, aus Fragmenten wieder
zusammengesetzte Pakete mit einer Größe von mindestens 1500 Byte zu
empfangen. Für IPv4 beträgt dieser Wert nur 576 Byte. Im anderen Extrem
darf ein IPv6-Paket auch fragmentiert laut Payload-Length-Feld im
IPv6-Header die Größe von 65.575 Byte einschließlich Kopfdaten nicht
überschreiten, da dieses Feld 16 Bit lang ist (216 − 1
Bytes zzgl. 40 Bytes Kopfdaten). ![]() RFC 2675 stellt aber über eine Option des Hop-by-Hop
Extension Headers die Möglichkeit zur Verfügung, Pakete mit Größen bis zu
4.294.967.335 Byte, sogenannte Jumbograms zu erzeugen. Dies
erfordert allerdings Anpassungen in Protokollen höherer Schichten, wie
z.B. TCP
oder UDP,
da diese oft auch nur 16 Bit für Größenfelder definieren, außerdem muss bei
jedem Paket, welches einen Jumbogram beinhaltet, im IPv6-Header die
Payload-Length auf 0 gesetzt werden.
RFC 2675 stellt aber über eine Option des Hop-by-Hop
Extension Headers die Möglichkeit zur Verfügung, Pakete mit Größen bis zu
4.294.967.335 Byte, sogenannte Jumbograms zu erzeugen. Dies
erfordert allerdings Anpassungen in Protokollen höherer Schichten, wie
z.B. TCP
oder UDP,
da diese oft auch nur 16 Bit für Größenfelder definieren, außerdem muss bei
jedem Paket, welches einen Jumbogram beinhaltet, im IPv6-Header die
Payload-Length auf 0 gesetzt werden.
Erweiterte ICMP-Funktionalität
ICMPv6 (Protokolltyp 58) stellt für das Funktionieren von IPv6 unverzichtbare Funktionen zur Verfügung. Das Verbieten aller ICMPv6-Pakete in einem IPv6-Netzwerk durch Filter ist daher im Normalfall nicht durchführbar.
Insbesondere wird das Address Resolution Protocol (ARP) durch das Neighbor Discovery Protocol (NDP) ersetzt, welches auf ICMPv6 basiert. Dieses macht hierbei intensiv Gebrauch von Link-Local-Unicast-Adressen und Multicast, das von jedem Host beherrscht werden muss. Im Rahmen des NDPs werden auch die automatische Adressvergabe und die automatische Zuordnung einer oder mehrerer Default-Routen über ICMPv6 abgewickelt, so stellt es die meisten Funktionen zur Verfügung, die oben unter IPv6-Autokonfiguration erklärt wurden. NDP kann auf die Möglichkeit weiterer Konfiguration durch DHCPv6 verweisen, welches allerdings UDP-Pakete benutzt.
Die Fragmentierung
überlanger IPv6-Pakete erfolgt nicht mehr durch die Router,
der Absender wird stattdessen mit Hilfe von ICMPv6-Nachrichten aufgefordert,
kleinere Pakete, auch unter Zuhilfenahme des Fragment Extension Headers,
zu schicken (siehe in diesem Zusammenhang Maximum
Transmission Unit (MTU)). Idealerweise sollte ein IPv6-Host, bzw. eine
Anwendung vor dem Versenden einer großen Anzahl von IPv6-Paketen eine Path
MTU Discovery gemäß ![]() RFC 1981 durchführen, um Pakete mit maximal möglicher Größe
verschicken zu können.
RFC 1981 durchführen, um Pakete mit maximal möglicher Größe
verschicken zu können.
IPv6 und DNS
Wegen der Länge der IP-Adressen, die an das menschliche Erinnerungsvermögen
höhere Anforderungen stellt als IPv4-Adressen, ist IPv6 in besonderem Maße von
einem funktionierenden Domain
Name System (DNS) abhängig. ![]() RFC 3596 definiert den Resource
Record (RR) Typ AAAA
(sprich: Quad-A), der genau wie ein A
Resource Record für IPv4 einen Namen in eine IPv6-Adresse auflöst. Der Reverse
Lookup, also die Auflösung einer IP-Adresse in einen Namen, funktioniert
nach wie vor über den RR-Typ PTR,
nur ist für IPv6 die Reverse Domain nicht mehr IN-ADDR.ARPA wie für IPv4,
sondern IP6.ARPA und die Delegation von Subdomains darin geschieht
nicht mehr an 8-Bit-, sondern an 4-Bit-Grenzen.
RFC 3596 definiert den Resource
Record (RR) Typ AAAA
(sprich: Quad-A), der genau wie ein A
Resource Record für IPv4 einen Namen in eine IPv6-Adresse auflöst. Der Reverse
Lookup, also die Auflösung einer IP-Adresse in einen Namen, funktioniert
nach wie vor über den RR-Typ PTR,
nur ist für IPv6 die Reverse Domain nicht mehr IN-ADDR.ARPA wie für IPv4,
sondern IP6.ARPA und die Delegation von Subdomains darin geschieht
nicht mehr an 8-Bit-, sondern an 4-Bit-Grenzen.
Ein IPv6-fähiger Rechner sucht in der Regel mittels DNS zu einem Namen
zunächst nach dem RR-Typ AAAA, dann nach dem RR-Typ A. Laut der Default
Policy Table in ![]() RFC 3484 wird die Kommunikation über IPv6 gegenüber IPv4
bevorzugt, falls festgestellt wird, dass für eine Verbindung beide Protokolle
zur Verfügung stehen. Die Anwendungsreihenfolge der Protokolle ist meistens aber
auch im Betriebssystem
und auf der Anwendungsebene, also z.B. im Browser,
einstellbar.
RFC 3484 wird die Kommunikation über IPv6 gegenüber IPv4
bevorzugt, falls festgestellt wird, dass für eine Verbindung beide Protokolle
zur Verfügung stehen. Die Anwendungsreihenfolge der Protokolle ist meistens aber
auch im Betriebssystem
und auf der Anwendungsebene, also z.B. im Browser,
einstellbar.
Alle dreizehn Root-Nameserver und mindestens zwei Nameserver der meisten Top-Level-Domains sind über IPv6 erreichbar. Das übertragende Protokoll ist unabhängig von den übertragenen Informationen. Insbesondere kann man über IPv4 einen Nameserver nach AAAA-RRs fragen. Anbieter großer Portalseiten denken jedoch darüber nach, nur DNS-Anfragen, die über IPv6 gestellt werden, auch mit AAAA Resource Records zu beantworten, um Probleme mit fehlerhaft programmierter Software zu vermeiden.
Übergangsmechanismen
| IPv6-Übergangsmechanismen | |
|---|---|
| 4in6 | Tunneling von IPv4 in IPv6 |
| 6in4 | Tunneling von IPv6 in IPv4 |
| 6over4 | Transport von IPv6-Datenpaketen zwischen Dual-Stack Knoten über ein IPv4-Netzwerk |
| 6to4 | Transport von IPv6-Datenpaketen über ein IPv4-Netzwerk (veraltet) |
| AYIYA | Anything In Anything |
| Dual-Stack | Netzknoten mit IPv4 und IPv6 im Parallelbetrieb |
| Dual-Stack Lite (DS-Lite) | Wie Dual-Stack, jedoch mit globaler IPv6 und Carrier-NAT IPv4 |
| 6rd | IPv6 rapid deployment |
| ISATAP | Intra-Site Automatic Tunnel Addressing Protocol (veraltet) |
| Teredo | Kapselung von IPv6-Datenpaketen in IPv4-UDP-Datenpaketen |
| NAT64 | Übersetzung von IPv4-Adressen in IPv6-Adressen |
| 464XLAT | Übersetzung von IPv4- in IPv6- in IPv4-Adressen |
| SIIT | Stateless IP/ICMP Translation |
IPv4 und IPv6 lassen sich auf derselben Infrastruktur, insbesondere im Internet, parallel betreiben. Für den Übergang werden also in der Regel keine neuen Leitungen, Netzwerkkarten oder Geräte benötigt, sofern dafür geeignete Betriebssysteme zur Verfügung stehen. Es gibt zurzeit kaum Geräte, welche IPv6, aber nicht gleichzeitig auch IPv4 beherrschen. Damit jedoch Geräte, die ausschließlich über IPv4 angebunden sind, auch mit Geräten kommunizieren können, die ausschließlich über IPv6 angebunden sind, benötigen sie Übersetzungsverfahren.
Um einen einfachen Übergang von IPv4- zu IPv6-Kommunikation im Internet zu ermöglichen, wurden verschiedene Mechanismen entwickelt. IPv6 wird dabei in der Regel hinzugeschaltet, ohne IPv4 abzuschalten. Grundlegend werden folgende drei Mechanismen unterschieden:
- Parallelbetrieb (Dual-Stack)
- Tunnelmechanismen
- Übersetzungsverfahren
Parallelbetrieb und Tunnelmechanismen setzten voraus, dass die Betriebssysteme der angebundenen Rechner beide Protokolle beherrschen.
Es gibt bereits heute Bereiche des Internets, die ausschließlich mittels IPv6 erreichbar sind, andere Teile, die über beide Protokolle angebunden sind und große Teile, die sich ausschließlich auf IPv4 verlassen. Im Folgenden werden die ersten beiden Bereiche zusammen als IPv6-Internet bezeichnet.
Dual-Stack
Bei diesem Verfahren werden allen beteiligten Schnittstellen neben der IPv4-Adresse zusätzlich mindestens eine IPv6-Adresse und den Rechnern die notwendigen Routinginformationen zugewiesen. Die Rechner können dann über beide Protokolle unabhängig kommunizieren, d.h. sowohl mit IPv4- als auch mit IPv6-fähigen Systemen Daten austauschen. Dieses Verfahren sollte der Regelfall sein, es scheitert derzeit oft daran, dass einige Router (meistens die Zugangsserver des Internetproviders oder die Heimrouter bei den Kunden) auf dem Weg zum IPv6-Internet noch keine IPv6-Weiterleitung eingeschaltet haben oder unterstützen.
Dual-Stack Lite (DS-Lite)
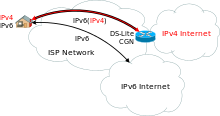
Aufgrund der knappen IPv4-Adressen hat die IETF den Mechanismus „Dual-Stack
Lite“ (![]() RFC 6333) entwickelt. Hierbei werden dem Kunden nur via IPv6
global routbare IP-Adressen bereitgestellt. (Im regulären Dual-Stack-Betrieb
werden sowohl IPv6 als auch IPv4 zur Verfügung gestellt.)
RFC 6333) entwickelt. Hierbei werden dem Kunden nur via IPv6
global routbare IP-Adressen bereitgestellt. (Im regulären Dual-Stack-Betrieb
werden sowohl IPv6 als auch IPv4 zur Verfügung gestellt.)
Im LAN des Kunden werden private IPv4-Adressen benutzt (analog zum Vorgehen bei NAT). Statt einer NAT-Übersetzung werden die IPv4-Pakete dann durch das Customer Premises Equipment (CPE) in IPv6-Pakete gekapselt. Das CPE benutzt seine globale IPv6-Verbindung, um die Pakete in das Carrier-grade NAT (CGN) des Internet Service Providers zu transportieren, welches über globale IPv4-Adressen verfügt. Hier wird das IPv6-Paket entpackt und das originale IPv4-Paket wiederhergestellt. Danach wird das IPv4-Paket mit NAT auf eine öffentliche IP-Adresse umgesetzt und ins öffentliche IPv4-Internet geroutet. Das Carrier-grade NAT identifiziert Sitzungen eindeutig mittels Aufzeichnungen über die öffentliche IPv6-Adresse des CPEs, die private IPv4-Adresse und TCP- oder UDP-Portnummern.
Diese DS-Lite-Umsetzung führt allerdings beim Endkunden zu Problemen: Zum einen sind bei portbasierten Protokollen (z.B. TCP, UDP) keine IPv4-basierenden Portfreigaben mehr möglich, da die Pakete an die öffentliche IP-Adresse bereits beim Provider ausgefiltert werden. Dienste, die an einem DS-Lite-Anschluss angeboten werden, können also von Geräten, die keine IPv6-Verbindungen aufbauen können, nicht erreicht werden. Auch werden vom CGN-Gateway nur bestimmte Protokolle verstanden und weitergeleitet, was die Nutzung anderer IP-basierter Protokolle erschwert oder völlig unmöglich macht.
Tunnelmechanismen
Um Router, die IPv6 nicht weiterleiten, auf dem Weg zum IPv6-Internet zu überbrücken, gibt es eine Vielzahl von Tunnelmechanismen. Dabei werden IPv6-Pakete in den Nutzdaten anderer Protokolle, meist IPv4, zu einer Tunnelgegenstelle übertragen, die sich im IPv6-Internet befindet. Dort werden die IPv6-Pakete herausgelöst und zum Ziel via IPv6-Routing übertragen. Der Rückweg funktioniert analog. Jedes Tunnelverfahren ist abhängig von der Qualität des tunnelnden Protokolls: der Weg der Pakete zum Ziel ist wegen des Umwegs über die Tunnelgegenstelle meistens nicht optimal und die mögliche Nutzlast sinkt, da mehr Kopfdaten übertragen werden müssen.
Der klassische Weg ist es, bei einem so genannten Tunnelbroker eine solche Gegenstelle für den privaten Gebrauch gebührenfrei zu beantragen. Diese Gegenstelle bleibt fest, und man bekommt über den Tunnel immer den gleichen IPv6-Adressbereich zugewiesen. 6in4 benutzt zum Beispiel den Protokolltyp 41, um IPv6 direkt in IPv4 zu kapseln. Für Linux ist die Erstellung eines solchen Tunnels mit den Interface-Konfigurationswerkzeugen möglich. Bei Windows ist dies seit Windows 10 April 2018 (1803) nicht mehr möglich. Komplizierter sind die Verfahren 6over4 oder ISATAP.
Der Mechanismus 6to4 benötigt keine Absprache mit einer Gegenstelle, denn diese benutzt im Internet definierte (Anycast)-IPv4-Adressen, und die getunnelten Pakete werden zur nächstgelegenen Gegenstelle zugestellt und dort verarbeitet. Dem angebundenen Rechner steht dann ein IPv6-Adressbereich zur Verfügung, der sich aus dessen öffentlicher IPv4-Adresse errechnet. Auch ein solcher Tunnel kann auf aktuellen Linux-Rechnern mit öffentlicher IPv4-Adresse durch wenige Handgriffe eingerichtet werden.
Befindet sich ein Rechner in einem privaten IPv4-Adressbereich und findet beim Verbinden mit dem Internet NAT statt, so können Mechanismen wie AYIYA oder Teredo helfen. Diese Protokolle kapseln IPv6-Pakete als Nutzdaten meist in UDP-Paketen. Erlaubt ein Administrator diese Protokolle, kann schnell die Netzwerksicherheit in Gefahr geraten, wenn der Paketfilter die Nutzdaten nicht als IPv6-Pakete interpretieren kann und somit eventuell andere Paketfilterregeln umgangen werden.
Es ist auch möglich, IPv6 über allgemeinere Tunnelverfahren wie GRE, L2TP oder MPLS zu transportieren, insbesondere, wenn noch Routingprotokolle wie IS-IS parallel übertragen werden müssen.
Übersetzungsverfahren
Kann auf einem Gerät IPv6 nicht aktiviert werden oder stehen nicht mehr
genügend IPv4-Adressen zur Verfügung, können Verfahren wie Network Address
Translation/Protocol Translation (NAT-PT, ![]() RFC 2766;
inzwischen missbilligt),
oder Transport Relay Translation (TRT,
RFC 2766;
inzwischen missbilligt),
oder Transport Relay Translation (TRT, ![]() RFC 3142) nötig
werden, um zwischen beiden Protokollen zu übersetzen.
Auch bieten Proxy-Server für
einige Protokolle höherer Schichten die Möglichkeit einer Kommunikation zwischen
beiden Welten.
RFC 3142) nötig
werden, um zwischen beiden Protokollen zu übersetzen.
Auch bieten Proxy-Server für
einige Protokolle höherer Schichten die Möglichkeit einer Kommunikation zwischen
beiden Welten.
Das Verfahren NAT64 bietet eine recht befriedigende Lösung, solange die Hauptanforderung darin besteht, von IPv6-Hosts initiierte Verbindungen an IPv4-Hosts weiterzuleiten.
Technische Umsetzung
Die ![]() RFC 6434 (IPv6 Node Requirements) gibt einen Überblick über
Funktionen, die alle IPv6-Geräte umsetzen sollten, um eine maximale
Interoperabilität zu gewährleisten. In diesem Dokument wird auf die jeweiligen
Spezifikationen verwiesen.
RFC 6434 (IPv6 Node Requirements) gibt einen Überblick über
Funktionen, die alle IPv6-Geräte umsetzen sollten, um eine maximale
Interoperabilität zu gewährleisten. In diesem Dokument wird auf die jeweiligen
Spezifikationen verwiesen.
Betriebssysteme
Viele Betriebssysteme unterstützen inzwischen IPv6, ein Überblick folgt. Entscheidend für eine tunnelfreie Anbindung ist aber auch die Unterstützung durch die Firmware, bzw. die Betriebssysteme, auf den (DSL-)Routern bei Endkunden und den Zugangsservern bei den Providern. Systeme (z.B. CDN) zur Lastverteilung, wie sie z.B. für große Webseiten eingesetzt werden, wurden und werden stückweise um IPv6 ergänzt.
- AIX
- Seit AIX 4 Version 4.3 ist IPv6 implementiert, seit AIX 5L Version 5.2 ist auch Mobile IPv6 implementiert.
- Android
- Android unterstützt IPv6 seit Version 2.1, jedoch nicht über die 3GPP-Schnittstelle. Seit 2.3.4 werden IPv6 APN unterstützt. Es fehlte allerdings bei den meisten Endgeräten die Unterstützung im UMTS Chipset (bzw. der Firmware). Ab Version 4.0 Ice Cream Sandwich sind Privacy Extensions standardmäßig aktiviert.
- BSD-Varianten
- IPv6 wird von den BSDs bereits sehr lange und sehr umfassend unterstützt (zum Beispiel bei FreeBSD seit März 2000, bei NetBSD seit Dezember 2000 und bei OpenBSD seit Mitte 2000). Die Unterstützung ist zu großen Teilen dem KAME-Projekt zu verdanken, das seit 1998 einen freien Protokollstapel für IPv6 und IPsec für BSD-Betriebssysteme entwickelt hatte.
- Cisco
- IPv6 wird ab IOS Version 12.2T experimentell, ab den Versionen 12.3 und 12.4 produktiv unterstützt. Auf älteren Geräten und Karten ist das IPv6-Forwarding aufgrund der Hardwareausstattung jedoch nur in Software, also mit Hilfe des Hauptprozessors möglich, was die Leistung gegenüber IPv4 deutlich vermindert.
- HP-UX
- Seit der Version 11iv2 ist IPv6 Bestandteil des Basissystems, frühere 11.x-Versionen können mit TOUR (Transport Optional Upgrade Release) IPv6-fähig gemacht werden.
- iOS (Apple iPhone, iPad, iPod Touch, Apple TV)
- Apple-Geräte mit iOS ab Version 4 unterstützen IPv6 im Dual-Stack-Modus. Privacy Extensions werden jedoch erst ab Version 4.3 unterstützt.
- Juniper
- Der Hersteller unterstützt IPv6 auf seinen Routern im Betriebssystem JunOS ab Version 5.1. Das IPv6-Forwarding geschah hier schon früh in Hardware, also ohne die Routing Engine (den Hauptprozessor) zu belasten. Für Firewall-Systeme, sowohl auf der ScreenOS Serie(ScreenOS <6.x), als auch auf der SRX Serie(JunOS <10.x) ist IPv6 unterstützt.
- Linux
- Der Kernel
bietet seit Version 2.6 eine produktiv einsetzbare IPv6-Unterstützung auf
ähnlichem Niveau wie die BSD-Derivate. Der Kernel 2.4 bietet eine als
experimentell ausgewiesene Unterstützung für IPv6, der jedoch noch wichtige
Eigenschaften wie IPSec und Datenschutzerweiterungen (Privacy Extensions, RFC 4941) fehlen. Die meisten Linux-Distributionen haben im
Auslieferungszustand mit Kerneln ab Version 3.x die Privacy Extensions
eingeschaltet, diese können jedoch manuell deaktiviert werden. Eine
experimentelle IPv6-Implementation ist auch in der Kernel-Version 2.2
enthalten.
- Mac OS X
- Seit Version 10.2 enthält auch Mac OS X Unterstützung für IPv6 auf der Basis von KAME. Erst seit Version 10.3 lässt sich IPv6 auch über die GUI konfigurieren. IPv6 ist standardmäßig aktiviert und unterstützt DNS-AAAA-Records. Die zur Apple-Produktfamilie gehörenden Airport-Extreme-Consumer-Router richten standardmäßig einen 6to4-Tunnel ein und fungieren als IPv6-Router. Die Privacy Extensions sind seit 10.7 (Lion) per Default aktiviert.
- OpenVMS
- Mit HP TCP/IP Services for OpenVMS Version 5.5 unterstützt HP OpenVMS (ab Version 8.2) IPv6.
- Solaris
- Seit der Version 8 ist die Unterstützung von IPv6 auch in dem Betriebssystem der Firma Sun Microsystems in begrenzter Form enthalten (die Implementierung und große Teile der Betriebssystemapplikationen erfordern immer noch, dass IPv4 konfiguriert ist), das für SPARC- und i386-Rechnerarchitekturen zur Verfügung steht. Die Konfiguration erfolgt analog zu den Linux- und xBSD-Systemen.
- Symbian OS
- Seit der Version 7.0 ist IPv6 fester Bestandteil des Systems. Es sind nur wenige Parameter über die GUI zu konfigurieren.
- Windows
- Seit Windows XP Service Pack 1 bringt Windows einen Protokollstapel für IPv6 mit. Die Unterstützung für IPv6 ist seither durch Microsoft stetig ausgebaut und aktuellen Entwicklungen angepasst worden. Seit Windows 8 wird IPv6 als bevorzugtes Protokoll verwendet, falls der Host an ein Dual-Stack-Netzwerk angeschlossen ist.
- Windows Server
- Seit Windows Server 2003 enthält Windows Server einen „Production-Quality“-Protokollstapel. Die Unterstützung für IPv6 ist in den seither erschienenen Versionen von Windows Server kontinuierlich von Microsoft ausgebaut worden.
- Windows Phone
- Windows Phone 7 und 7.5 unterstützen IPv6 nicht. Erst ab Version 8 ist ein IPv6-Stack integriert.
- z/OS
- IBM z/OS unterstützt IPv6 seit September 2002 vollständig, schon 1998 gab es für den Vorgänger OS/390 einen experimentellen Stack.
Routing
Während statisches Routing für IPv6 analog zu IPv4 eingerichtet werden kann,
ergeben sich für die dynamischen Routingprotokolle
einige Änderungen. Zwischen Autonomen
Systemen wird das Border
Gateway Protocol mit den Multiprotocol Extensions (definiert in
![]() RFC 4760) eingesetzt. Als Interior Gateway
Protocol stehen OSPF
in der Version 3, IS-IS mit Unterstützung von
IPv6-TLVs
und RIPng
als offene Standards zur Verfügung. Die meisten Hersteller unterstützen für
IS-IS Multi-Topology Routing, also gleichzeitiges Routing für beide
Adressfamilien auch dann, wenn IPv4- und IPv6-Netz sich nicht genau überdecken.
OSPFv3 realisiert dieses in einem sehr neuen Standard (
RFC 4760) eingesetzt. Als Interior Gateway
Protocol stehen OSPF
in der Version 3, IS-IS mit Unterstützung von
IPv6-TLVs
und RIPng
als offene Standards zur Verfügung. Die meisten Hersteller unterstützen für
IS-IS Multi-Topology Routing, also gleichzeitiges Routing für beide
Adressfamilien auch dann, wenn IPv4- und IPv6-Netz sich nicht genau überdecken.
OSPFv3 realisiert dieses in einem sehr neuen Standard (![]() RFC 5838) über
verschiedene Instanzen für die verschiedenen Protokolle, war ursprünglich aber
nur für IPv6 vorgesehen. Ein anderer Weg ist es unterschiedliche
Routingprotokolle für die beiden Topologien
zu verwenden, also etwa OSPFv2 für IPv4 und IS-IS für IPv6.
RFC 5838) über
verschiedene Instanzen für die verschiedenen Protokolle, war ursprünglich aber
nur für IPv6 vorgesehen. Ein anderer Weg ist es unterschiedliche
Routingprotokolle für die beiden Topologien
zu verwenden, also etwa OSPFv2 für IPv4 und IS-IS für IPv6.
An Endsysteme können eine oder mehrere Default-Routen per Autokonfiguration oder DHCPv6 übergeben werden. Mit DHCPv6-PD (Prefix Delegation) können auch Präfixe zwecks weiteren Routings zum Beispiel an Kundenrouter verteilt werden.
Da weder RSVP noch LDP für IPv6 ausreichend standardisiert sind, müssen sich MPLS-Netze weiter auf die Signalisierung mittels IPv4 verlassen, können jedoch, abhängig von der Implementierung, IPv6-Verkehr transportieren. Für IPv6 Multicast-Routing ist PIM geeignet.
Paketfilter und Firewalls
Für IPv6 müssen alle Filterregeln in Firewalls und Paketfiltern neu erstellt werden. Je nachdem, ob der filternde Prozess den IPv6-Datenverkehr überhaupt verarbeitet und abhängig von ihrer Default-Policy kann eine Firewall IPv6 ungehindert durchlassen. Auch einige Antivirenprogramme haben Zusätze, welche den Verkehr z.B. auf bestimmten TCP-Ports nach Signaturen durchsuchen. Für Linux kann die Filterung von IPv6 mit dem Programm ip6tables (seit Version 3.13 des Linux-Kernels auch nft/nftables) konfiguriert werden.
Deutliche Veränderungen in der Struktur der Filter gegenüber IPv4 können sich ergeben, sofern sie ICMP bzw. ICMPv6 behandeln, da sich dessen Protokollnummer, Type- und Code-Zuordnungen sowie die Funktionalität verändern.
Das Feld Next Header im IPv6-Header eignet sich nicht in gleicher Weise wie das Protocol-Feld im IPv4-Header zum Identifizieren von Protokollen höherer Schicht, denn im Falle der Verwendung von Extension Headers verändert sich dessen Wert, beispielsweise bei Fragmentierung.
Einige Aspekte von NAT wurden in der Vergangenheit oft als
Sicherheitsfunktion verstanden; NAT ist in IPv6 jedoch höchstens in
Ausnahmefällen vorgesehen. ![]() RFC 4864 beschreibt Vorgehensweisen, welche diese Aspekte von
NAT mit IPv6-Techniken abbilden;
so kann etwa die bei einigen Implementierungen bestehende Funktion von NAT, neu
eingehende Verbindungen nicht an Rechner des Heimnetzes weiterzuleiten, durch
einen zustandsbehafteten
Paketfilter im Router ersetzt werden. Dieser kann nach Wunsch neu eingehende
Verbindungen generell abweisen oder diese nur für bestimmte Bereiche des
Heimnetzes zulassen.
RFC 4864 beschreibt Vorgehensweisen, welche diese Aspekte von
NAT mit IPv6-Techniken abbilden;
so kann etwa die bei einigen Implementierungen bestehende Funktion von NAT, neu
eingehende Verbindungen nicht an Rechner des Heimnetzes weiterzuleiten, durch
einen zustandsbehafteten
Paketfilter im Router ersetzt werden. Dieser kann nach Wunsch neu eingehende
Verbindungen generell abweisen oder diese nur für bestimmte Bereiche des
Heimnetzes zulassen.
Anwendungssoftware
Für Anwendungen wie Webbrowser oder E-Mail-Programme sind Änderungen in der Programmierung notwendig, damit sie über IPv6 kommunizieren können. Dies ist für die wichtigsten Programme, die mit aktuellen Betriebssystemen ausgeliefert werden, bereits geschehen, nicht aber bei weniger häufig benutzten Anwendungen.
In den meisten Fällen sind nur kleinere Änderungen notwendig, da die Anwendungen auf Protokolle höherer Schicht aufsetzen und diese sich kaum ändern. In vielen Betriebssystemen forderten die Programmierschnittstellen jedoch von der Anwendung, Sockets explizit zur IPv4-Kommunikation anzufordern. Neuere Schnittstellen sind in der Regel so gestaltet, dass IPv6-unterstützende Anwendungen automatisch auch IPv4 unterstützen. Verarbeiten die Anwendungen Inhalte mit URLs, wie sie in HTTP oder im Session Initiation Protocol (SIP) vorkommen, so müssen sie die URL-Notation von IPv6-Adressen unterstützen.
Zum Teil sind Änderungen notwendig, um die Leistung der Anwendung nicht zu mindern: So muss z.B. eine eventuell ermittelte, verminderte Path MTU an die Anwendung übergeben werden, um Fragmentierung zu vermeiden oder die Maximum Segment Size (MSS) im TCP-Header muss bei IPv6 gegenüber IPv4 verringert werden. Viele Programmiersprachen stellen spezielle Bibliotheken zur Verfügung, um den Umgang mit dem neuen Protokoll zu vereinfachen.
Administration
Die Hauptarbeit der Umsetzung liegt auf der Verwaltungsebene: Administration und Support müssen geschult, Dokumentationen und Konfigurationen, z.B. für Routing, Firewalls, Netzwerküberwachung, das Domain Name System und evtl. DHCP, müssen während der Übergangsphase für beide Protokolle erstellt und gepflegt werden. In vielen Dokumentationen oder Fehlermeldungen muss im Nachhinein zwischen IPv4 und IPv6 unterschieden werden, wo noch vor einigen Jahren nur von IP die Rede war. Die Struktur des IP-Netzes wird zunächst quasi verdoppelt.
Oft haben IP-Adressen eine Bedeutung auf höherer Ebene. So tauchen sie in Logdateien oder Netflow-Daten auf, die teilweise mit Skripten wie beispielsweise Webalizer weiterverarbeitet werden, um Ansichten, Statistiken oder Abrechnungen zu erzeugen. Auch das Layout und die Skripte zur Erzeugung von Seiten wie Wikipedias „Versionsgeschichte“ mussten an die IPv6-Notation angepasst werden, da hier Nutzer zum Teil mit ihrer IP-Adresse identifiziert werden. Basiert eine Rechteverwaltung, wie z.B. in vielen Datenbanken, auf dem Zugriff durch festgelegte IP-Adressen, muss dies beim Zuschalten von IPv6 berücksichtigt werden.
Verbreitung und Projekte
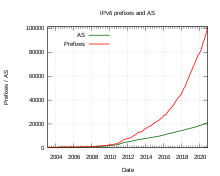
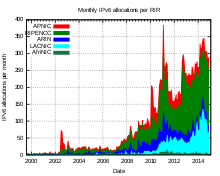
IPv6 setzt sich im praktischen Einsatz nur langsam durch. Die Adressvergabe für IPv6 ist im Juli 1999 vom experimentellen in den Regelbetrieb übergegangen und immer mehr ISPs betreiben neben IPv4 auch IPv6 in ihrem Netz.
Über den Internetknoten AMS-IX werden zu Spitzenzeiten 150 GBit/s IPv6-Traffic transportiert, das sind etwa 3 % des dort anfallenden Gesamtverkehrs von 5 TBit/s. Auf Webseiten im Dual-Stack Betrieb werden weltweit 27 % der Zugriffe über IPv6 gemessen, für Zugriffe aus Deutschland liegt der IPv6-Anteil bei 46 %.
Die globale IPv6-Routingtabelle umfasste im Oktober 2016 etwa 33000 Präfixe, und ungefähr 26 % aller im Internet verfügbaren Autonomen Systeme beteiligen sich am globalen IPv6-Routing. Die meisten der großen Austauschpunkte für Internetverkehr erlauben und fördern neben IPv4 auch den Austausch von IPv6 über ihre Infrastruktur. Beim DE-CIX nutzten im April 2008 etwa 70 bis 80 von insgesamt 240 Providern IPv6.
Das IPv6 Forum wurde im Juli 1999, der Deutsche IPv6 Rat im Dezember 2007 gegründet. Das IPv6 Forum Projekt IPv6-Ready vergibt das IPv6-Logo in drei verschiedenen Stufen, die die Implementierung des Protokolls messen. Die Webseite listet dazu auch alle IPv6-fähigen Betriebssysteme auf.
Derzeit sind 74 % aller IPv4-Adressen den nordamerikanischen Internet Registries und einigen US-amerikanischen Institutionen und Unternehmen direkt zugewiesen, während beispielsweise ganz China – mit inzwischen über 250 Millionen Internet-Benutzern (Stand: Juni 2008) – vor Jahren noch nur über etwa so viele IP-Adressen verfügte wie ein Campus der University of California (Dezember 2004).
Von Seiten der Endbenutzer wird IPv6 auch deshalb nicht gefordert, weil außer dem größeren Adressbereich die wesentlichen neuen Eigenschaften von IPv6 inzwischen mehr oder weniger erfolgreich nach IPv4 zurückportiert wurden (beispielsweise IPsec, QoS, Multicast; Umnummerierung und Autokonfiguration sind auch mittels DHCP möglich) – es gibt keine weitverbreitete Anwendung, die nur mit IPv6 funktionieren würde.
Frühe Projekte
In Deutschland federführend bei den Versuchen zu IPv6 war das JOIN-Projekt der Universität Münster. JOIN und der Verein zur Förderung eines Deutschen Forschungsnetzes (DFN) haben mit dem „6WiN“ einen ersten IPv6-Backbone in Deutschland aufgebaut. Das 6WiN war ein ringförmiger Backbone durch Deutschland mit Querverbindung zwischen Essen und Berlin. Parallel dazu baute die Deutsche Telekom einen eigenen IPv6-Backbone zwischen den Standorten Darmstadt, Münster und Berlin auf und bot ihren Geschäftskunden im Rahmen eines Showcase-Projektes Anschluss daran an. Dieses Netz war in Münster und Berlin mit dem 6WiN verbunden. Ebenfalls in Münster lag der deutsche zentrale Zugang zum experimentellen IPv6-Netzwerk 6Bone, der am 7. Juni 2005 im Rahmen der planmäßigen sukzessiven Beendigung des weltweiten 6Bone-Betriebs abgeschaltet wurde. Zum 1. Januar 2006 wurde der IPv6-Betrieb im Deutschen Forschungsnetz vom JOIN-Projekt an das DFN-NOC übergeben.
Die Universität Wien, die auch den Vienna Internet Exchange (VIX) und mehrere DNS-Server für die Zone „.at“ betreibt, spielte eine entscheidende Rolle bei der IPv6-Migration in Österreich. Beide Einrichtungen sind über IPv6 erreichbar bzw. bieten akademischen Kunden IPv6-Anbindung an. Der erste kommerzielle Anbieter in Österreich war das Unternehmen next layer.
Anbindung von Endnutzern
Am 8. Juni 2011 fand der sogenannte World IPv6 Day statt, an dem der Dual-Stack-Betrieb auf mehreren großen Webseiten getestet wurde. Der Test verlief weitestgehend problemlos. Am Internetknotenpunkt DE-CIX war ein deutlich erhöhtes IPv6-Verkehrsaufkommen zu messen, das auch nach dem 8. Juni anhielt.
Im Rahmen eines weiteren Aktionstages am 6. Juni 2012, dem World IPv6 Launch Day, haben mehr als 1400 Unternehmen weltweit ihre Webseiten dauerhaft auf den neuesten Standard umgestellt, so dass sie mit IPv4 und IPv6 erreichbar sind.
Seit dem 25. September 2012 leistet die Deutsche Telekom IPv6 auch an DSL-Endkundenanschlüssen. Zunächst wurden erst die sogenannten IP-Anschlüsse IPv6-fähig gemacht, wobei zunächst mit Neukunden begonnen wurde. Die mittlerweile deaktivierten Analog- und ISDN-Anschlüsse erhielten kein IPv6. In der aktuellen Leistungsbeschreibung für die Nutzung von LTE an einer fest vereinbarten Adresse („MagentaZuhause via Funk“ als Alternative zu DSL) stellt die Deutsche Telekom z.B. klar, dass über diesen Internetzugang nur IPv4-Adressen erreichbar sind.
Nutzer weiterer Anschlussarten wie beispielsweise dem Mobilfunknetz oder Kabel werden zunehmend mit IPv6 versorgt.
Probleme
Historisch
Gerade zu Anfang wurden die IPv6-Standards häufig geändert, was dazu führte, dass bereits fertiggestellte Implementierungen mehrfach angepasst werden mussten.
Adressierung der Netzknoten
Der größte Einschnitt bestand in der Einführung der IEEE-Norm
EUI-64 für die
Interface-Identifier
als Teil der Adressen. Um die Einzigartigkeit einer Adresse im Netzwerk auf
einfache Weise zu garantieren, wurde vorher die
MAC-Adresse
einer Schnittstelle
unverändert in die IPv6-Adresse übernommen, nun wird die MAC-Adresse gemäß
EUI-64 in veränderter Form in die IPv6-Adresse geschrieben; dabei wird aufgrund
einer Verwechslung in ![]() RFC 3513 der Algorithmus, um EUI-64-Namen aus EUI-48-Namen zu
berechnen, fälschlicherweise auf MAC-48-Namen angewandt.
RFC 3513 der Algorithmus, um EUI-64-Namen aus EUI-48-Namen zu
berechnen, fälschlicherweise auf MAC-48-Namen angewandt.
Die beschriebenen Verfahren führen zu einem statischen hostspezifischen Teil
der IPv6-Adresse eines autokonfigurierten IPv6-Knotens. Datenschützer waren
besorgt, dass auf diese Weise Nutzer über unterschiedliche Netzwerke hinweg
identifizierbar werden und dies beispielsweise für Marketingmaßnahmen oder
staatliche Interventionen ausgenutzt werden könnte. Die IETF
definierte deshalb nachträglich die Datenschutzerweiterungen (Privacy
Extensions) gemäß ![]() RFC 3041, später
RFC 3041, später ![]() RFC 4941 (siehe auch Adressaufbau
von IPv6). Diese Privacy-Extensions generieren bei der Autokonfiguration via
SLAAC einen zufälligen hostspezifischen Teil. Da aber die ersten 64 Bit der
IPv6-Adresse eines Netzes (z.B. eines Haushaltes) weiterhin erhalten
bleiben, muss ein weiterer Schutz durch regelmäßiges Wechseln des
netzspezifischen Teils gewährleistet sein (wie heute bei DSL-Anschlüssen).
RFC 4941 (siehe auch Adressaufbau
von IPv6). Diese Privacy-Extensions generieren bei der Autokonfiguration via
SLAAC einen zufälligen hostspezifischen Teil. Da aber die ersten 64 Bit der
IPv6-Adresse eines Netzes (z.B. eines Haushaltes) weiterhin erhalten
bleiben, muss ein weiterer Schutz durch regelmäßiges Wechseln des
netzspezifischen Teils gewährleistet sein (wie heute bei DSL-Anschlüssen).
Integration ins Domain Name System
Lange Zeit war die DNS-Anpassung zur Eingliederung von IPv6 uneinheitlich.
1995 wurde in ![]() RFC 1886 zunächst der Record-Typ AAAA für die Auflösung von
DNS-Namen in IPv6-Adressen definiert, der funktional äquivalent zum A-Record für IPv4
ist. Im Jahr 2000 wurde AAAA in
RFC 1886 zunächst der Record-Typ AAAA für die Auflösung von
DNS-Namen in IPv6-Adressen definiert, der funktional äquivalent zum A-Record für IPv4
ist. Im Jahr 2000 wurde AAAA in ![]() RFC 2874 durch den Record-Typ A6 abgelöst, der vor allem das
Umnummerieren vereinfachen sollte, indem die IP-Adresse stückweise auf das DNS
abgebildet wurde, jedoch nie frei von technischen Problemen war. 2003 wurde das
Verfahren A6 daher in
RFC 2874 durch den Record-Typ A6 abgelöst, der vor allem das
Umnummerieren vereinfachen sollte, indem die IP-Adresse stückweise auf das DNS
abgebildet wurde, jedoch nie frei von technischen Problemen war. 2003 wurde das
Verfahren A6 daher in ![]() RFC 3596 wieder nach „experimentell“ zurückgestuft, und AAAA
wurde der neue, alte Standard.
RFC 3596 wieder nach „experimentell“ zurückgestuft, und AAAA
wurde der neue, alte Standard.
Noch mehr Schwierigkeiten bereitete die Rückwärtsauflösung („Reverse“-Auflösung) von IPv6-Adressen, da es aufgrund der Wechsel der Standards PTR-Records in zwei verschiedenen Zonen gab, unterhalb von ip6.arpa und ip6.int. Aufgrund der traditionellen Nutzung der TLD .arpa für die Rückwärtsauflösung bei IPv4 hat sich die erstere Variante gegen ip6.int durchgesetzt, woraufhin die Delegierung von ip6.int im Juni 2006 gelöscht wurde.
Die Auflösung ist vom Protokolltyp der Anfrage völlig unabhängig: Wird eine DNS-Anfrage über IPv4 gestellt, so kann auch ein AAAA-Record zurückgegeben werden, und über IPv6 erreichbare Nameserver geben auch über IPv4-Adressen (A-Records) Auskunft.
Aktuell
Link-lokale Adressen
Eine mögliche Designschwäche von IPv6 ist, dass die Adressräume für link-lokale
Adressen grundsätzlich nicht getrennt sind. Will man link-lokale Adressen
also auf Anwendungsebene zur Kommunikation zwischen Rechnern im selben
Netzwerksegment verwenden, ergibt sich das Problem, dass es für diese nicht
ausreichend ist, die IP-Adresse im Ziel-Feld einzutragen, sondern auch ein
Zone Index nach ![]() RFC 4007 (in den meisten Fällen
ein Interface) angegeben
werden muss, da sich der link-lokale Adressraum mehrerer Interfaces
überschneidet. Es hängt daher davon ab, ob die IPv6-Unterstützung der
verwendeten Anwendung das Konzept der Zonen-Indizes kennt, ob link-lokale
Adressen zu diesem Zweck eingesetzt werden können.
RFC 4007 (in den meisten Fällen
ein Interface) angegeben
werden muss, da sich der link-lokale Adressraum mehrerer Interfaces
überschneidet. Es hängt daher davon ab, ob die IPv6-Unterstützung der
verwendeten Anwendung das Konzept der Zonen-Indizes kennt, ob link-lokale
Adressen zu diesem Zweck eingesetzt werden können.
Autokonfiguration und DNS
Im Zusammenspiel des IPv6-Autokonfigurationsmechanismus mit dem Domain Name System ergeben sich bis heute Probleme. Ursprünglich fehlte die Möglichkeit ganz, im Rahmen der Autokonfiguration Netzknoten auch zu verwendende DNS-Server und weitere DNS-bezogene Informationen wie DNS-Suchpfade mitzuteilen, wie das für IPv4 im Rahmen von DHCP üblich ist. Heute bestehen im Wesentlichen zwei Lösungen für das Problem:
- Mittels des Managed-Flags in Router-Advertisements können
Netzknoten angewiesen werden, bei einem DHCPv6-Server
nach weiterer Konfiguration zu fragen. DHCPv6-Server können über die
Multicastadressen
ff02::1:2undff05::1:3angesprochen werden. Im Gegensatz zu DHCP muss der DHCPv6-Server keine Protokolle über solche Anfragen führen, die Konfiguration kann also weiterhin zustandslos erfolgen. - Die NDP-Spezifikation erlaubt die Angabe zusätzlicher Felder in Router Advertisements. Die so genannten RDNSS- (Recursive DNS Server) und DNSSL-Erweiterungen (DNS Search List) spezifizieren eine Möglichkeit, DNS-Server und DNS-Suchpfade im Rahmen der Router Advertisements zu versenden.
Insbesondere RDNSS und DNSSL sind erst im November 2010 mit Erscheinen von ![]() RFC 6106 standardisiert worden.
RFC 6106 standardisiert worden.
Die Unterstützung für die obengenannten Lösungen ist unter den verschiedenen Implementierungen uneinheitlich. Beispielsweise unterstützen Microsoft Windows Vista und 7 nur DHCPv6 und für Linux-Systeme sind zwar alle Verfahren verfügbar, jedoch oft von Distributoren nicht vorinstalliert. Mac OS X unterstützt allerdings seit der Version 10.7 (Lion) sowohl DHCPv6 als auch RDNSS.
Datenschutz
Datenschützer bemängeln an IPv6, dass hier jedes mit dem Internet verbundene Gerät eine fixe IP-Adresse bekommen könnte, wodurch alle besuchten Seiten noch Jahre später eruiert und der Besucher identifiziert werden könnte. Technisch kann dies durch die Privacy Extensions erschwert werden.
Bereits 64 Bit große Adressen hätten einen unvorstellbaren Vorrat von weit über 1019 Adressen dargestellt – eine Milliarde mal 10 Milliarden, quasi eine Milliarde Generationen der Menschheit. Mit den 128 Bit, die man bei IPv6 verwendet, sind es sogar 1038. Damit könnte man theoretisch jedem Atom jedes Menschen auf der Welt eine eigene Adresse zuteilen.
Da es so niemals zu einer Verknappung kommen kann, sind technische Vorrichtungen wie bei IPv4 überflüssig geworden, wodurch ein Internetnutzer teilweise alle paar Stunden eine andere IP-Adresse zugewiesen bekam. Bei IPv6 haben Privatpersonen praktisch eine feste IP-Adresse, die für Webtracking ein Segen ist. Jede IPv6-Adresse kann sehr zuverlässig einem Haushalt oder sogar Mobiltelefon zugeordnet werden. Dadurch kann z.B. eine Suchmaschine oder Onlineshop Personen identifizieren und Informationen über sie verknüpfen, ohne sich Zugriff auf fremde Rechnersysteme zu verschaffen. Dies erforderte ursprünglich so genannte „Tracking Cookies“. Mit genügend Verbreitung von IPv6-Adressen wird dieses Verfahren obsolet.
Um dieses Problem zu umgehen, wollen Datenschützer Internet Service Provider per Gesetz dazu verpflichten, auch unter IPv6 dynamische Adressen anzubieten.
IPv5
Ein Protokoll mit dem Namen IPv5 gibt es nicht. Allerdings hat die IANA
die IP-Versionsnummer 5 für das Internet Stream Protocol Version 2
(ST2, definiert in ![]() RFC 1819) reserviert, das gegenüber IPv4 verbesserte Echtzeitfähigkeiten haben
sollte, dessen Entwicklung dann aber aus Kosten-Nutzen-Erwägungen zugunsten von
IPv6 und RSVP
eingestellt wurde.
RFC 1819) reserviert, das gegenüber IPv4 verbesserte Echtzeitfähigkeiten haben
sollte, dessen Entwicklung dann aber aus Kosten-Nutzen-Erwägungen zugunsten von
IPv6 und RSVP
eingestellt wurde.
Literatur
Grundlegende Spezifikationen
- RFC
2460. – Internet
Protocol, Version 6 (IPv6) Specification. (Aktualisiert durch RFC
8200 – im Juli 2017 abgelöst – englisch).
- RFC
4861. – Neighbor
Discovery for IP version 6 (IPv6). (englisch).
- RFC
4862. – IPv6
Stateless Address Autoconfiguration. (englisch).
- RFC
4291. – IP Version
6 Addressing Architecture. (englisch).
- RFC
5942. – IPv6 Subnet
Model. (englisch).
Sekundärliteratur
- Reiko Kaps: WAN-Auffahrt – Mit dem IPv6-Netz online gehen. In: c’t, Heise, Hannover 2008,6.
- Silvia Hagen: IPv6. Grundlagen – Funktionalität – Integration. Sunny Edition, Maur 2009, ISBN 978-3-9522942-2-2.
- Anatol Badach: Technik der IP-Netze. TCP/IP incl. IPv6. Funktionsweise, Protokolle und Dienste. Hanser Fachbuch. 2. Auflage. Hanser, München 2007, ISBN 3-446-21935-8.
- Mathias Hein: IPv6, Das Migrationshandbuch. Franzis, Point 2003, ISBN 3-7723-7390-9.
- Hans P. Dittler: IPv6. Das neue Internet-Protokoll. Technik, Anwendung, Migration. 2. Auflage. Dpunkt, Heidelberg 2002, ISBN 3-89864-149-X.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 06.04. 2023